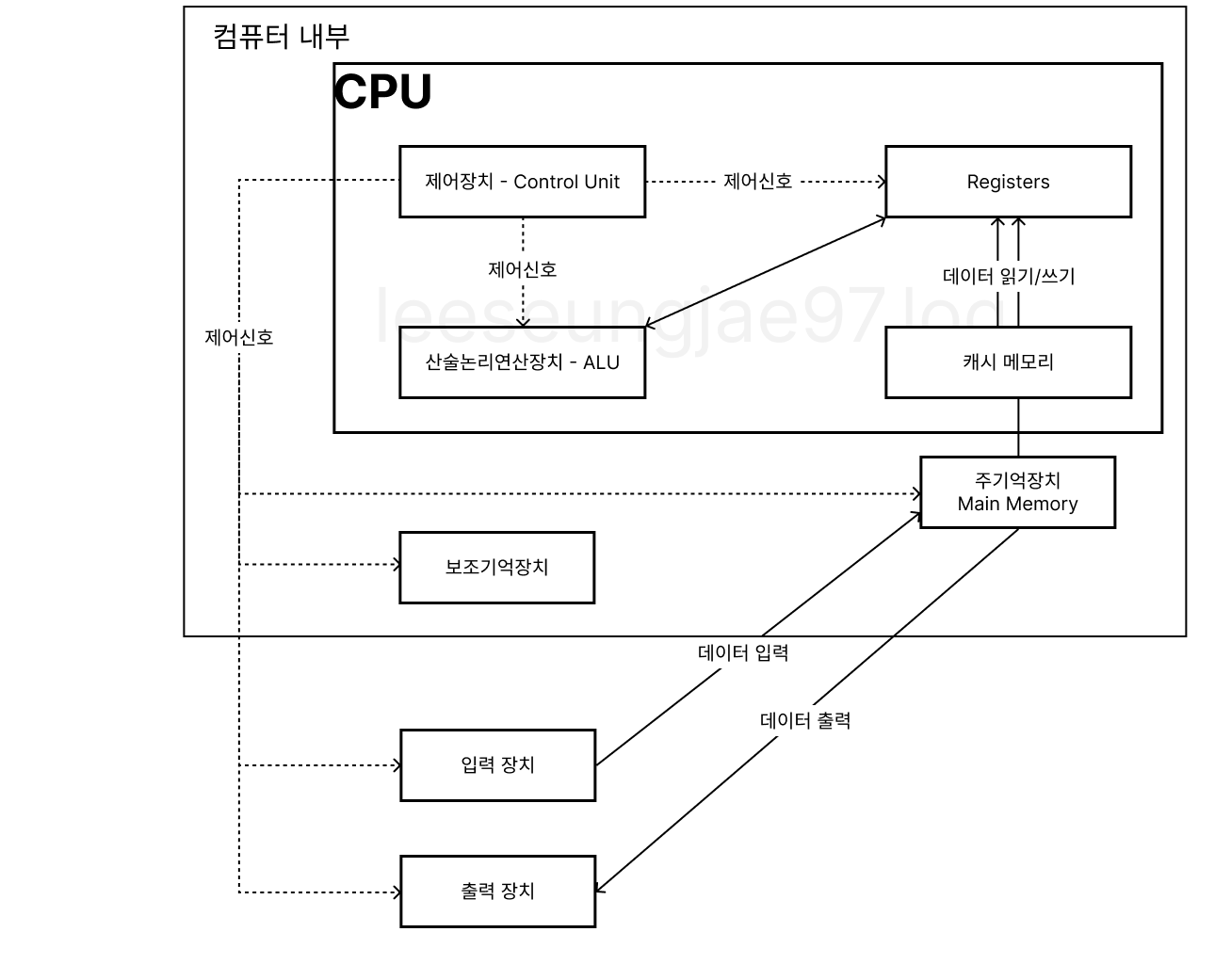
CPU
기억장치에서 명령어를 읽어와 해석하고 실행하는 장치
- ALU(Arithmetic Logic Unit)
- 산술, 논리, 비트, 비교
- CU(Control unit) : 메모리에서 명령어를 가져와, 해석해 제어신호 보냄
- 레지스터: CPU내부 고속 임시 저장장치
주기억장치
보조기억장치
- 비휘발성 저장 장치, 전원이 꺼져도 데이터를 영구적으로 보관
- 프로그램과 데이터를 영구적으로 저장, 필요할 때 메인 메모리로 로드
- HDD는 플래터 회전을 이용
- SSD는 플래시 메모리를 사용
RAID(Redundant Array of Independent Disks)
데이터의 안정성, 성능 확보를 위해
여러개의 보조 저장장치를 하나의 보조 저장장치처럼 사용하는 기술
| RAID 레벨 | 구성 방식 | 특징 | 장점 | 단점 |
|---|---|---|---|---|
| RAID 0 | 스트라이핑(Striping) | 데이터 블록을 여러 디스크에 분산 저장 | 가장 빠름 (성능 최고) | 내결함성 없음 (하나만 고장 나도 모든 데이터 손실) |
| RAID 1 | 미러링(Mirroring) | 동일한 데이터를 두 디스크에 중복 저장 | 데이터 안전성 최고 (하나 고장 나도 복구 가능) | 용량 손실 50% (비용 효율 낮음) |
| RAID 5 | 분산 패리티(Distributed Parity) | 데이터와 패리티(오류 검출/복구 정보)를 모든 디스크에 분산 저장 | 성능 & 안전성 균형, 용량 효율 좋음 (N-1/N) | 패리티 계산 오버헤드, 재구축 시간 김 |
| RAID 6 | 이중 분산 패리티(Dual Distributed Parity) | 두 개의 패리티 블록 사용 | RAID 5보다 높은 안전성 (디스크 2개 고장 허용) | RAID 5보다 쓰기 성능 저하, 더 복잡 |
| RAID 10 (1+0) | 미러링 + 스트라이핑 | RAID 1로 묶고 다시 RAID 0으로 묶음 | 성능 & 안전성 모두 우수 | RAID 1과 동일한 용량 손실 (50%) |
디스크 물리적으로, 논리적으로 파괴되어도 RAID로 묶은 다른 디스크가 있는 이상 데이터가 살아 있을 수 있음.
실제로 디스크가 파괴되면 그 안에 있는 데이터는 소실되는게 맞지만.
다른 디스크들의 남아 있는 정보를 조합해 사라진 데이터를 계산해 다시 만들어낼 수 있음.
디스크 A(데이터) : 3저장
디스크 B(데이터) : 5저장
디스크 P(패리티) : 3 xor 5 = 6
디스크 A가 파괴되어 소실되어도 패리티를 통해 3이 있었단걸 알 수 있음.
패리티가 파괴되는건 문제가 안됨 데이터는 존재하기 때문.
패리티와 디스크가 같이 파괴되면?
복구 가능한 양이라면(RAID6일 경우 두개까지 고장허용)패리티와 디스크가 같이 파괴되어도 복구가 가능함.
하지만 복구 가능한 한계량이 있기 때문에 백업은 항상 해야한다.
입·출력
- 프로그램 입출력 : 프로그램 속 명령어로 입출력 작업 수행
- 인터럽트 기반 입출력 : 하드웨어(마우스, 키보드)가 인터럽트 발생 (CPU가 실행 사이클 끝나면 인터럽트 확인)
- DMA 입출력 : CPU 대신 장치 컨트롤러와 상호작용해 입출력 작업 수행, DMA가 작업을 수행하고 CPU에 인터럽트
GPU
CPU보다 느린 다수의 개별 코어를 가짐
- VRAM : GPU 전용 메모리, GPU코어가 사용
HLSL(VS, CS)을 GPU가 수행하는 과정
GPU에는 CPU보다 훨씬 많은 ALU가 있음.
분기 처리에 약하고 사칙연산에 특화되어 있음.HLSL은 컴파일되면 어셈블리어 -> 기계어로 변환됨
결국 고레벨 언어이지만 GPU입장에서는 단순 연산과 다를것 없음.
빌드 과정
코드를 작성하고 수정해서 빌드를 하게되면
일련의 과정을 통해 실행 파일 .exe를 만든다.
각 과정은 크게 전처리 → 컴파일 → 어셈블 → 링크 단계로 나뉜다.
- 전처리는 컴파일러가 번역하기 전, 소스 코드를 정리하는 단계이다.
#include한 내용을 추가하고,#define된 상수들을 실제 값으로 치환한다.
전처리 결과로 확장된 소스 텍스트가 만들어진다. - 컴파일은 고수준의 언어(C++)를 특정 아키텍처(x86-64)가 이해할 수 있는 어셈블리어로 번역하는 단계.
컴파일러가 번역한다.
타입, 선언, 정의 체크, 참조 검사, 문장 검사등이 이루어진다.
여기서 발생하는 에러를 컴파일 에러라고 한다. - 어셈블 단계에서 컴파일 단계에서 변환된 어셈블리어를 0과 1로된 기계어로 변환한다.
이때 나온 결과물이.obj확장자로 저장된다.목적 파일이라고 부른다.
CPU가 바로 실행 할 수 있는 이진 명령어가 들어있지만 실제주소는 비어있다.func로 점프해라 라는 말은 있는데func가 메모리 몇 번지에 있는지 모른다. - 링크 단계에서 심볼 해석과 재배치 정보 정리를 수행해서 파일/라이브러리를 만든다.
여러개의 목적파일(.obj)파일과 라이브러리를 묶어 실행 파일(.exe)를 만든다.
우리가 코드를 작성하다 syntax가 틀려 나오는 에러를 컴파일 에러라고 한다.
그런데 컴파일은 빌드 과정 중 하나이다. 그리고 우리가 코드를 작성하는건 코드 편집단계로 빌드 이전의 단계이다.
이 경우에는 IDE가 내부적으로 요약버전 전처리 → 컴파일을 해주기 때문에 문법 검사가 가능하다.
IDE는 자체 파서와 인덱싱 정보를 이용해
문맥 분석, 문법 검사, 자동완성을 제공한다.
이 과정에서 전처리 정보를 일부 활용한다.
이게 #include <vector>를 하고 vec만 처도 추천코드가 뜰 수 있는 이유이다.
운영체제 32bit, 64bit
n비트 주소 공간을 가진 시스템에서는,
바이트 단위 주소 지정 기준으로 이론상
최대 $2^n$ byte의 주소 공간을 표현할 수 있다.
대부분의 CPU에서는 메모리 주소가 레지스터에 저장되기 때문에,
보통 레지스터 크기는 주소 폭보다 크거나 같다.
따라서 주소 공간은 레지스터 크기보다 작을 수 있지만 일반적으로 더 크지는 않다.
8비트 주소 공간을 가진 시스템, 표현 가능한 값의 가짓수
$2^8 = 256byte$ == 최대 256byte 주소 공간
16비트 주소 공간을 가진 시스템, 표현 가능한 값의 가짓수
$2^{16} == 65,536byte$ == 최대 64KB 주소 공간
32비트 주소 공간을 가진 시스템, 표현 가능한 값의 가짓수
$2^{32} == 4,294,967,296byte$ == 최대 4GB 주소 공간
64비트 주소 공간을 가진 시스템, 표현 가능한 값의 가짓수
$2^{64} == 18,446,744,073,709,551,616byte$ == 최대 16EB 주소 공간
8bit == 1byte
1024byte == 1KB
1024KB == 1MB
1024MB == 1GB,
1024GB == 1TB,
1024TB == 1PB(페타),
1024PB == 1EB(엑사), (제타, 요타..)컴퓨터구조상 연산을 하려면 숫자가 레지스터를 거쳐가야하므로,
레지스터 크기가 컴퓨터에서 한번에 부를 수 있는 수의 크기를 나타낸다.
두번 불러서 큰 수를 처리할 수도 있지만 연산이 두번되는거니까
기존에 32bit로 최소 두번 이상 연산할 일을 64bit에선 한번만 하게 된다.
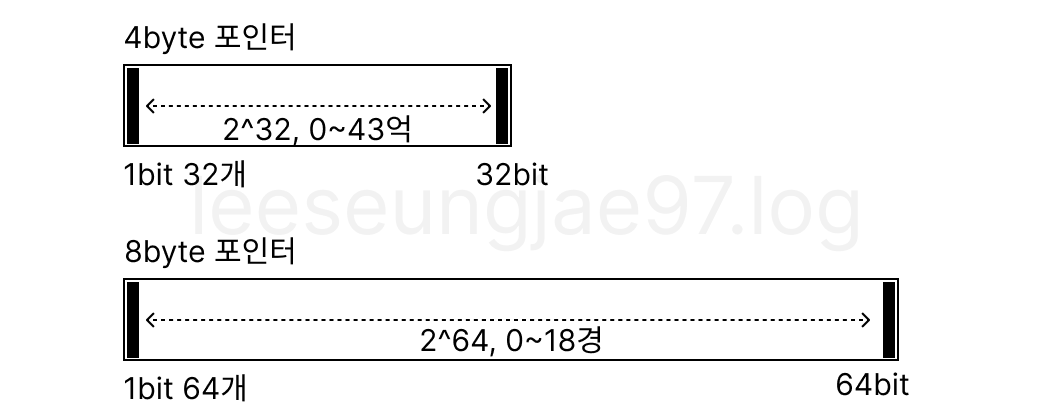
프로그래머 입장에서 제일 와닿는 변화는 포인터 변수 크기 변화일 것이다.
64bit 주소 공간을 사용하는 시스템에서는
이론적으로 $2^{64}$ byte 주소 공간을 표현할 수 있다.
$2^{64}$ 주소공간을 가리키기 위해
포인터가 8byte로 바뀌었다.
요즘 CPU는 64bit 뿐만 아니라
32bit 명령어도 알아 들을 수 있게 회로를 설계해서
64/32bit 둘 다 돌릴 수 있다.
여담
2003년 AMD64(x86-64)가 출시되고 Windows XP가 해당 방식을 채택해 만들어졌다.
그 이전에 개발된 프로그램들은 32bit 체제에서 개발되었는데,
32bit로 개발된 많은 프로그램들이 전환시도를 하고있다.라이브 서비스를 오래한 게임의 경우
그 전환이 최근에서야 이루어지고 있는걸 보면 보통 수고로운 일이 아니다.
visual studio는 2019까지 32bit 프로그램이였다.x86-64(x86의 64bit 확장)아키텍처를 채택한 여파로
Windows는 32bit 프로그램은 Program Files (x86)에 저장하고
64bit 프로그램은 Program폴더에 저장한다.
Underflow, Overflow
8bit 레지스터가 있을 때 $2^8 == 256$가지의 값을 표기할 수 있다. 0 ~ 255가 될 것이다.
비트로 따지면 `0000 0000 ~ 1111 1111이다.255(1111 1111)에 1을 더하면 값은1 0000 0000이 되고 9비트가 필요하다.
레지스터는 8칸 뿐이므로 맨 앞 1은 버려지고
레지스터에는0000 0000만 남게된다. 이걸Overflow`라고한다.
마찬가지로 8bit 레지스터가 있고, 0 ~ 255만 표기할 수 있다고 하자.(0000 0000) - (0000 0001)를 계산할 수 없으니 1을 빌려온다.
그럼 256(1 0000 0000) - 1(0000 0001)이 되고 255(1111 1111)가 된다.
이걸 Underflow라고 한다.
이번엔 32bit 이상의 레지스터가 있는 환경에서 부호가 있는 수를 생각해보자
int는 4byte 자료형으로 -2,147,483,648(약-21억) ~ 2,147,483,647까지 수를 담을 수 있다.
32비트는 총 $2^{32}$개의 비트 패턴이 있고
2의 보수 해석으로 그 절반 정도가 음수, 절반 정도가 0/양수로 매핑된다.
2의 보수
컴퓨터에서 음수를 표현하는 방식
2진수 비트를 반전(NOT, 1의 보수)시킨 후 1을 더해 구하는 방식
- 비트 반전 (1의 보수): 원본 2진수의 0은 1로,
1은 0으로 바꾼다. - 1 더하기: 1의 보수에 1을 더한다.
예:
3 (0000 0011)
→ 비트 반전 (1111 1100)
→ 1 더하기 (1111 1101) = -3.
최대수인 2,147,483,647의 비트는
$0111\ 1111\ 1111\ 1111\ 1111\ 1111\ 1111\ 1111^{(2)}$ 이다
여기에서 1을 더하면
$1000\ 0000\ 0000\ 0000\ 0000\ 0000\ 0000\ 0000^{(2)}$
0111 1111 1111 1111 1111 1111 1111 1111
+ 0000 0000 0000 0000 0000 0000 0000 0001
-----------------------------------------
1000 0000 0000 0000 0000 0000 0000 0000-2,147,483,648이 된다.
-2,147,483,648 - 1을 하면
부호 비트에서 1 빌려오기를 하면서 값이 바뀐다.
1000 0000 0000 0000 0000 0000 0000 0000
- 0000 0000 0000 0000 0000 0000 0000 0001
-----------------------------------------
0111 1111 1111 1111 1111 1111 1111 11112,147,483,647이 되었다.
소수
0과 1밖에 없는 bit단위에서 소수점을 직접 저장할 수 없다.
그래서 비트 단위의 약속을 통해 소수를 표기했다.
32bit로 표현하는 부동소수점을 단정도 소수(Single Precision Floating Point)라고하고
C++에서 자료형은 float이다.
64bit로 표현하는 부동소수점을 배정도 소수(Double Precision Floating Point)라고하며
C++에서 자료형은 double이다.
고정소수점(Fixed Point)
소수점의 위치를 고정시켜 사용하는 방식이다.
32bit 고정소수점(Q15.16 기준)은
32bit중 앞 1bit부호 15bit는 정수, 뒤 16bit는 소수자리다.
부호
0 000 0000 0000 0000 ← 여기까지 정수, 여기서부터 소수 →0000 0000 0000 000064bit 고정소수점(Q32.31 기준)은
64bit중 앞1bit 부호 31bit는 정수, 뒤 32bit는 소수자리가 된다.
소수 1.5로 저장되는 방식을 보자
1.5는 정수 1과 0.5이다
0.5 * 2 == 1.0에서 1빼고 나머지 00.5는
$1000\ 0000\ 0000\ 0000^{(2)}$으로 표기
1은 1이니까
$0000\ 0000\ 0000\ 0001^{(2)}$
합치면
정수는 정순 ← → 소수자리는 역순으로 표기
0000 0000 0000 0001 | 1000 0000 0000 00000.9일 땐
0.9 * 2 == 1.8 (1)
0.8 * 2 == 1.6 (1)
0.6 * 2 == 1.2 (1)
0.2 * 2 == 0.4 (0)
0.4 * 2 == 0.8 (0)
0.8 * 2 == 1.6 (1)
...반복된다 이렇게 반복되는 수는 16bit까지만 구하고 나머지는 버린다.
$1110\ 0110\ 0110\ 0110^{(2)}$
정수는 0이니까
$0000\ 0000\ 0000\ 0000\ .\ 1110\ 0110\ 0110\ 0110^{(2)}$
그래서 0.9는 실제로 0.899993896484375...와 같은 근사치로 저장된다.
이 방법은 정수를 계산하는것과 다를게 없어서 매우 빠르다
하지만 큰수나 아주 작은 수를 동시에 표현하기 어렵다.
부동소수점(Floating Point)
부동은 한자로 浮動으로 浮(뜰 부)에 動 (움직일 동)이다.
소수점이 떠서 움직인다 라는 뜻이다. 말 그대로 소수점 위치가 고정되지 않는다.
부동소수점은 IEEE754(협회이름(아이-트리플-이) + 문서번호)에서 정의한 방식으로 표현한다.
부호, 지수, 가수로 나뉜다. 부호는 부호고, 지수는 소수점이 몇 칸이나 움직일지 결정하고
가수는 실제 숫자의 모양을 나타낸다.
무한소수는 정규화 과정에서 반올림한다.
단정도 소수는 부호 1bit, 지수 8bit, 가수 23bit가 있다.
부호| 지수 | 가수
0|000 0000 0|000 0000 0000 0000 0000 0000배정도 소수는 부호 1bit, 지수 11bit, 가수 52bit다
고정소수점과 달리 지수부는 소수점이 이동할 위치를 결정하고
가수부에만 실제 숫자들이 저장된다.
소수점을 부동 소수점의 bit로 바꾸려면 일련의 과정이 있다.
정규화
2진수를 $1.XXXX... * 2^n$ 꼴로 바꿔야한다.
정수부에 1만 남을 때 까지 소수점을 왼쪽으로 이동 시키고
이동 시킨 칸수만큼 n자리에 넣으면 된다.
오른쪽으로 이동시키면 마이너스를 붙여주면 된다.소수점을 1만 남을 때 까지 이동 111.101 11.1101 (1) 1.11101 (2) 2칸 움직였다.$1.11101^{(2)} * 2^2$
$111.101^{(2)}(7.625)$을 정규화하면
정규화한 값을 단정도소수 기준 부호1, 지수8, 가수23에 맞추자
지수값 2를 bias라는 지정된 수와 더한 후,
2진수로 바꿔 지수부에 넣는다.2 + 127은 129이고 2진수로 바꾸면 $1000\ 0001^{(2)}$ 이다.
이걸 지수부에 집어넣자.부호 지수부 가수부 0 | 100 0000 1 | 111 0100 0000 0000 0000 0000
배정도소수 경우 bias가 1023이다.가수부는 똑같다.
부호 지수부 가수부 0 | 100 0000 0001 | 111 0100 0000 0000 0000 0000 0 ... 0 (52개)지수부는
2 + 1023 == $100\ 0000\ 0001^{(2)}$가수부에는 위에서 정규화해서 나온 소수점 아랫값($11101^{(2)}$)을 집어넣는다.
단정도(float)는 지수부가 8비트이므로 bias가 127이며, 실제 지수에 127을 더한 값을 지수 비트에 기록한다.
이걸로 32bit 고정소수점에서 오차를 냈던 0.9를 계산하면 오차가 없을까?
$0.1110\ 0110\ 0110\ 0110 \ 0110\ 0110 \ 0110 \ 0110 \ 0110 \ 0110 \ 0110 \ 0110\ 0110... ^{(2)}$
이걸 부동소수점 단정도소수와 부동소수점 배정도소수에 저장하자
단정도
$1.1100\ 1100\ 1100\ 1100\ 1100\ 111 * 2^{-1}$
$-1 + 127 = 0111 1110^{(2)}$
부호 지수부 가수부
0 | 011 1111 0 | 110 0110 0110 0110 0110 01110.89999997615814208984375
배정도
$1.1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1100\ 1101 * 2^{-1}$
$-1 + 1023 = 011\ 1111\ 1110^{(2)}$
부호 지수부 가수부
0 | 011 1111 1110 | 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1100 1101이 값은 0.89999999999999991118... 이다. 단정도소수에 비해서 오차가 줄었지만
그래도 오차가 있다.
부동소수점 오차
위에서본 0.9, 0.1 + 0.2 = 0.30000000000000004등 소수점오차가 발생한다.
이는 연산과정에서 지수 맞추기를 위해 가수부의 비트 범위를 벗어나기 때문이다.0.9같은 무한소수는 가수부에 맞추기위해 반올림해 사용한다. 이점도 오차가 발생하는 이유 중 하나다.
무한을 값 범위에 맞추기 위해 끼워넣다가 소실값이 생겨나는 것.
그래서 코드에서 소수를 비교할때 오차범위를 준다.
if(abs(a - 0.3) < 0.00001)decimal같은 오차 없는 특수 클래스도 있다.
NaN(Not a Number)
IEEE754에서 정의한 숫자가 아님을 뜻한다.
0/0, $\infty - \infty$ 또는 $\infty / \infty$, $\sqrt{-1}$, 숫자가 아닌것과 연산이 NaN이다.
NaN이 포함된 연산은 모두 NaN이 된다.
NaN은 비교 불능의 값이다 NaN끼리도 false. 비교하려면 isnan() 함수를 사용해야한다.
특수값: 부호(sign), 지수부(exponent), 가수부(significand)로 구성, 지수는 모두 1, 가수는 0이 아닌 상태
양의 무한대($+\infty$): 표현 가능한 가장 큰 실수를 넘는 값, 양수/0 나눗셈 결과로 생성.
음의 무한대($-\infty$): 표현 가능한 가장 작은(가장 음수에 가까운) 실수를 넘는 값, 음수/0 나눗셈 결과 생성.
무한대는 무한대 끼리 비교가능하다.
$+\infty$, $-\infty$은 소수의 Overflow이다.
반대로 너무 작은수를 구하려하면 부동소수점의 정규화 형태인 $1.XXXX... * 2^n$에서 1을 포기해버린다.
그럼 $0.XXXX... * 2^n$형태로 저장된다.(subnormal)
여기서 더 작은 수를 구하려고하면 그냥 0으로 처리한다.
범위 초과 방지
정수의 Overflow, Underflow를 방지하려면 long long(8byte)을 사용하거나
음수를 사용하지 않는다면 unsigned를 통해 표현 0 ~ 42억의 수를 표현가능하게 한다.
소수는 되도록 double을 쓰고 아예 오차가 나지 않아야 한다면 정수형 고정 소수점 방식을 쓴다.
범위 초과가 날 것 같은 값은 코드에서 예외처리한다.
bool safe_add(int a, int b)
{
// a + b > INT_MAX 인지 검사 (이항 정리하여 검사)
if (a > INT_MAX - b)
{
return false;
}
return true;
}
double result = some_complex_calculation();
if (std::isinf(result) || std::isnan(result))
{
// 에러 처리 또는 값 보정
}컴퓨터는 CPU 레지스터 크기(32/64bit)에 맞춰 메모리 주소와 데이터 처리 단위를 결정하며,
우리가 작성한 코드는 전처리, 컴파일, 링크를 거쳐 메모리 4대 영역(Code, Data, Heap, Stack)에 배치되어
CPU 명령어로 실행되는데, 이 과정에서 비트 단위의 표현 한계로 인해 정수의 오버플로우나
소수의 부동소수점 오차가 발생할 수 있다.
문제
20문제
https://gemini.google.com/share/45905f09faea
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.