운영체제
하드웨어 자원을 관리하고 응용 프로그램에 서비스를 제공하는 서비스 소프트웨어.
운영체제가 적재되는 메모리 영역이 커널영역이다.
그 외의 메모리 공간을 사용자 영역이라고 한다.
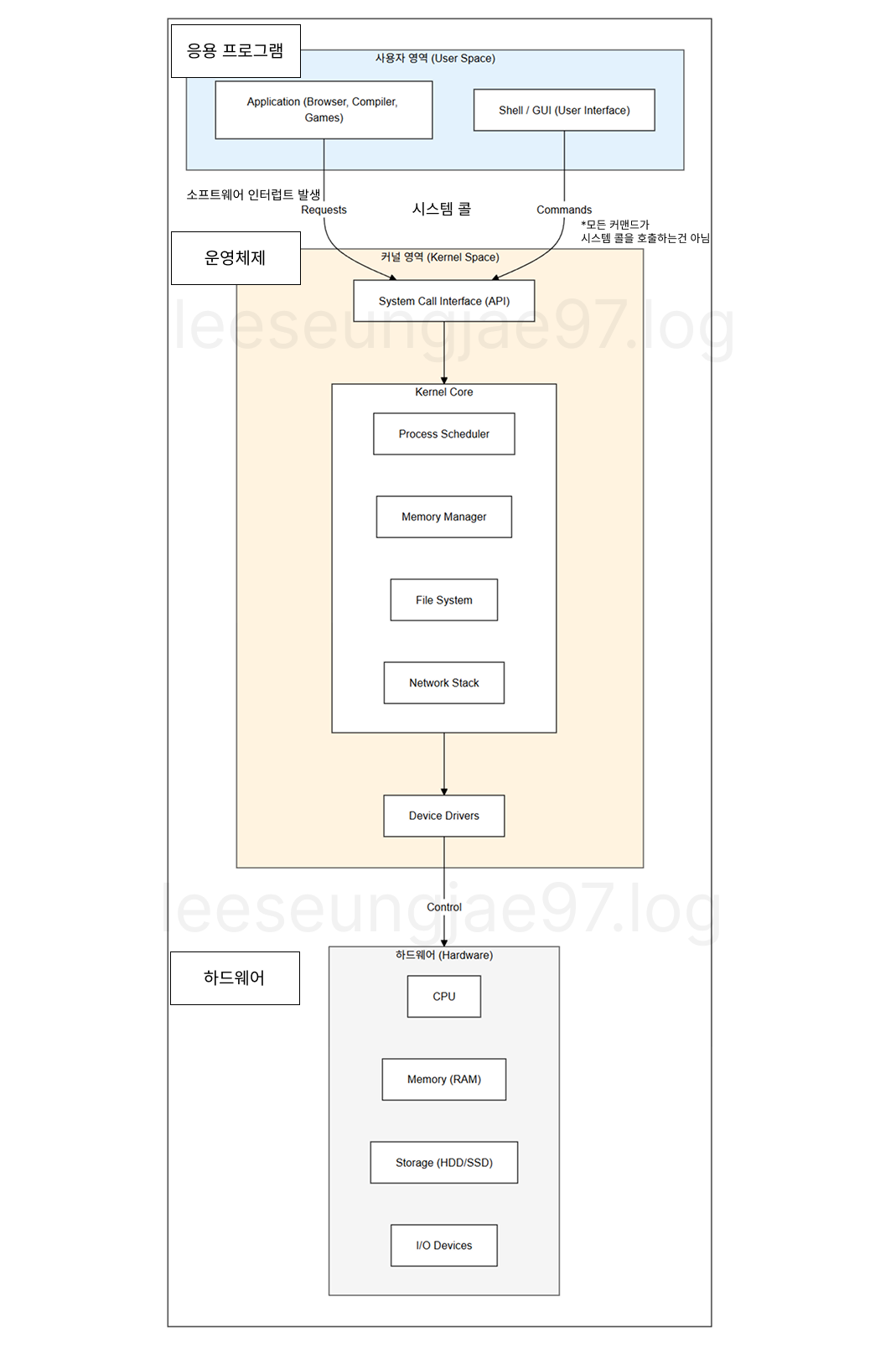
시스템 콜이라는 서비스 요청 인터페이스를 호출해
운영체제의 기능(프로세스 생성, 하드웨어 사용 등)을 사용할 수 있다.
시스템 콜은 소프트웨어 인터럽트의 일종으로
CPU가 수행하던 작업을 백업하고 시스템 콜을 처리한다.
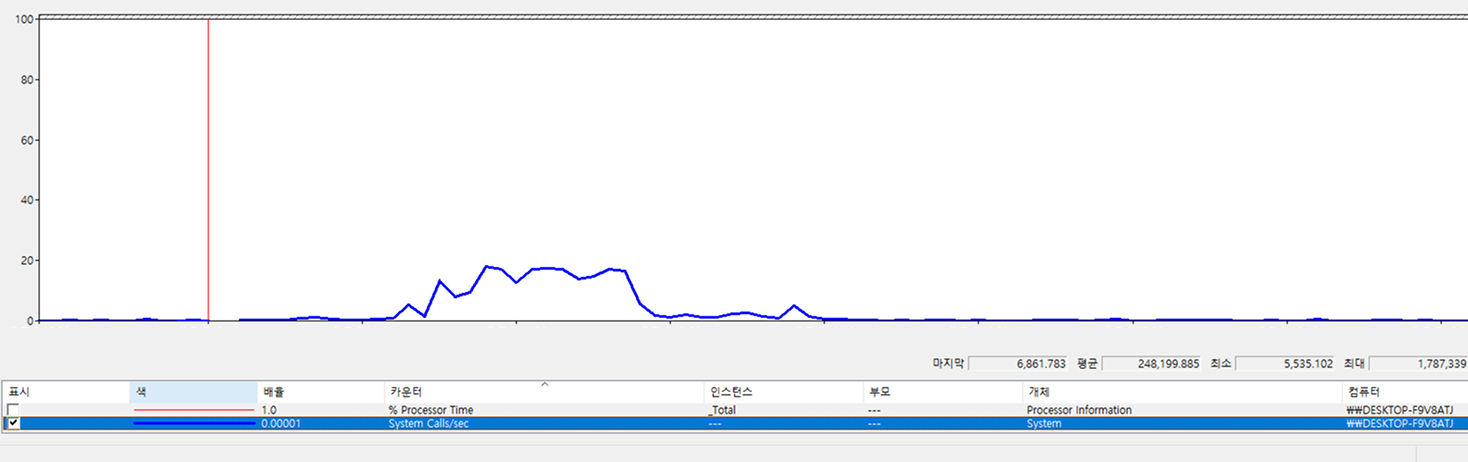
아래는 Windows perfmon에서 확인할 수 있는 시스템 콜
프로그램 - 운영체제 - 하드웨어 구조
핵심기능
- 프로세스 관리
- 메모리 관리
- 파일 시스템
- 입출력 시스템
- 보호 및 보안
커널(Kernel) 영역
컴퓨터가 부팅될 때 메모리에 가장 먼저 올라간다.
메모리에 상주하면서 시스템의 자원을 관리하고 제어한다.
프로세스 관리, 메모리 관리, 파일 시스템 관리, 시스템 콜, 장치 드라이버등을 관리 하고 제어하는 영역사용자는 시스템 콜을 통해 커널영역에 접근할 수 있다.
프로세스
OS로부터 자원을 할당받아 메모리에 적재되어 실행되고 있는 프로그램
프로그램이 메모리에 올라가 자원을 할당받으면 프로세스.
프로세스는 프로세서에 의해서 실행된다.
프로세서는 명령어를 해석하고 실행하는 주체(CPU, GPU)이다.
각 프로세스는 독립적인 메모리 공간을 가짐.
PCB(Process Control Block) : OS에서 프로세스들을 관리하기 위해 프로세스의 정보를 담은 자료구조
| 저장 정보 | 설명 |
|---|---|
| 프로세스의 현재 상태 | 준비, 대기, 실행등의 프로세스 상태 |
| 포인터 | - 부모 프로세스에 대한 포인터 : 부모 프로세스의 주소 기억 - 자식 프로세스에 대한 포인터 : 자식 프로세스의 주소 기억 - 프로세스가 위치한 메모리에 대한 포인터 : 현재 프로세스가 위치한 주소 기억 - 할당된 자원에 대한 포인터 : 프로세스ㅔ에 할당된 각 자원에 대한 주소 기억 |
| 프로세스 고유 식별자 | 프로세스를 구분할 수 있는 고유의 번호 |
| 스케줄링 및 프로세스의 우선순위 | 스케줄링 정보 및 프로세스가 실행될 우선순위 |
| CPU 레지스터 정보 | Accmulator, 인덱스 레지스터, 범용 레지스터, 프로그램 카운터 등에 대한 정보 |
| 주기억장칭 관리 정보 | Base Register, Page Table |
| 입·출력 상태 정보 | 입·출력장치, 개방된 파일 목록 |
| 계정 정보 | CPU 사용시간, 실제 사용 시간 |
- 각 프로세스는 생성될 때마다 고유의 PCB가 생성.
프로세스 상태 전이
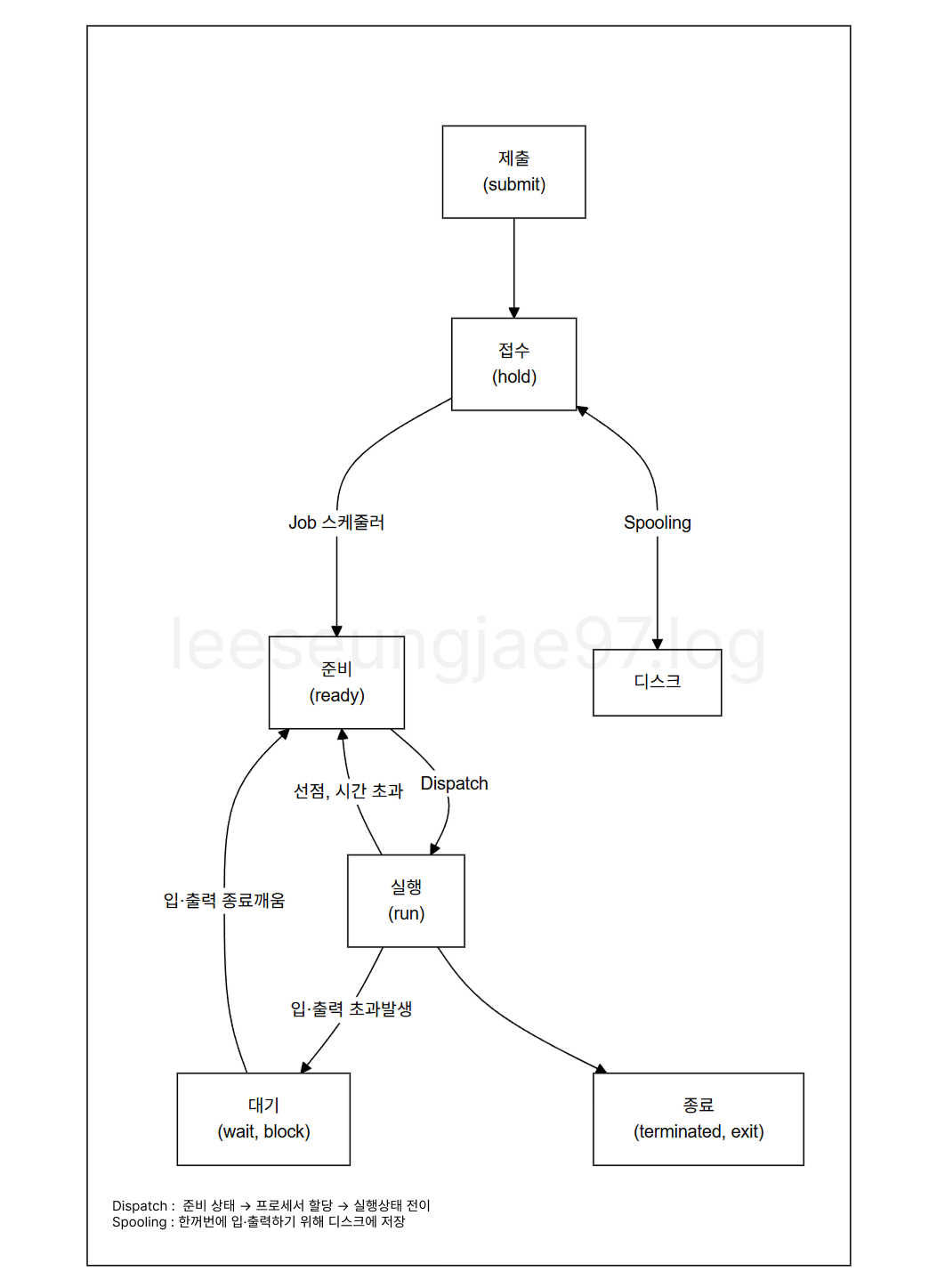
- 제출 : 사용자가 작업을 시스템에 제출
- 접수 : Spool 공간인 디스크의 할당 위치에 저장
- Spool : CPU와 느린 입출력 장치(프린터 등) 간의 속도 차이를 해소하기 위해
하드디스크의 일부분을 가상 버퍼로 활용하는 저장 영역
- Spool : CPU와 느린 입출력 장치(프린터 등) 간의 속도 차이를 해소하기 위해
- 준비
- 프로세스가 프로세서를 할당받기 위해 대기
- 프로세스는 준비상태큐에서 실행 준비
- Job 스케줄러가 접수상태에서 준비상태로 전이시킴
- 실행
- 프로세스가 프로세서를 할당받아 실행됨
- 할당 시간 종료되면 준비상태로 전이
- 입·출력 처리가 필요하면 대기상태로 전이
- CPU 스케줄러가 준비상태에서 실행상태로 전이시킴
- 대기 : 입·출력 처리가 완료될 때까지 대기
- 종료 : 프로세스 할당 해제
Context Switching : 다른 프로세스를 실행하기위해 현재 프로세스를 멈추고 교체하는 작업
IPC(Inter-process Communication)
독립적인 메모리 구조를 가지는 프로세스끼리 통신을 위한 메커니즘.
| IPC 종류 | 설명 | 특징 |
|-|-|
| 공유 메모리 (Shared Memory) | 특정 메모리 블록을 여러 프로세스가 공유 | 속도가 가장 빠름, 동기화 문제 발생 가능 |
| 파이프 (Pipe) | 부모-자식 간의 단방향 통신 통로 | 익명 파이프(단방향), 네임드 파이프(FIFO) |
| 소켓 (Socket) | 네트워크 인터페이스를 이용한 통신 | 원격 프로세스 간 통신 가능, 오버헤드 큼 |
| 메시지 큐 (Message Queue) | 커널이 관리하는 메시지 리스트 | 큐 구조로 데이터 관리, 비동기 처리에 유리 |
| 시그널 (Signal) | 비동기적인 이벤트 알림 (예: SIGKILL, SIGINT) | 데이터 전송보다는 상태 알림 목적 |
스레드
프로세스 내에서 실행되는 흐름 단위
- 프로세스의
Code,Data,Heap영역을 모든 스레드가 공유한다. Stack,Register,TLS영역은 각 스레드가 독립으로 가진다.
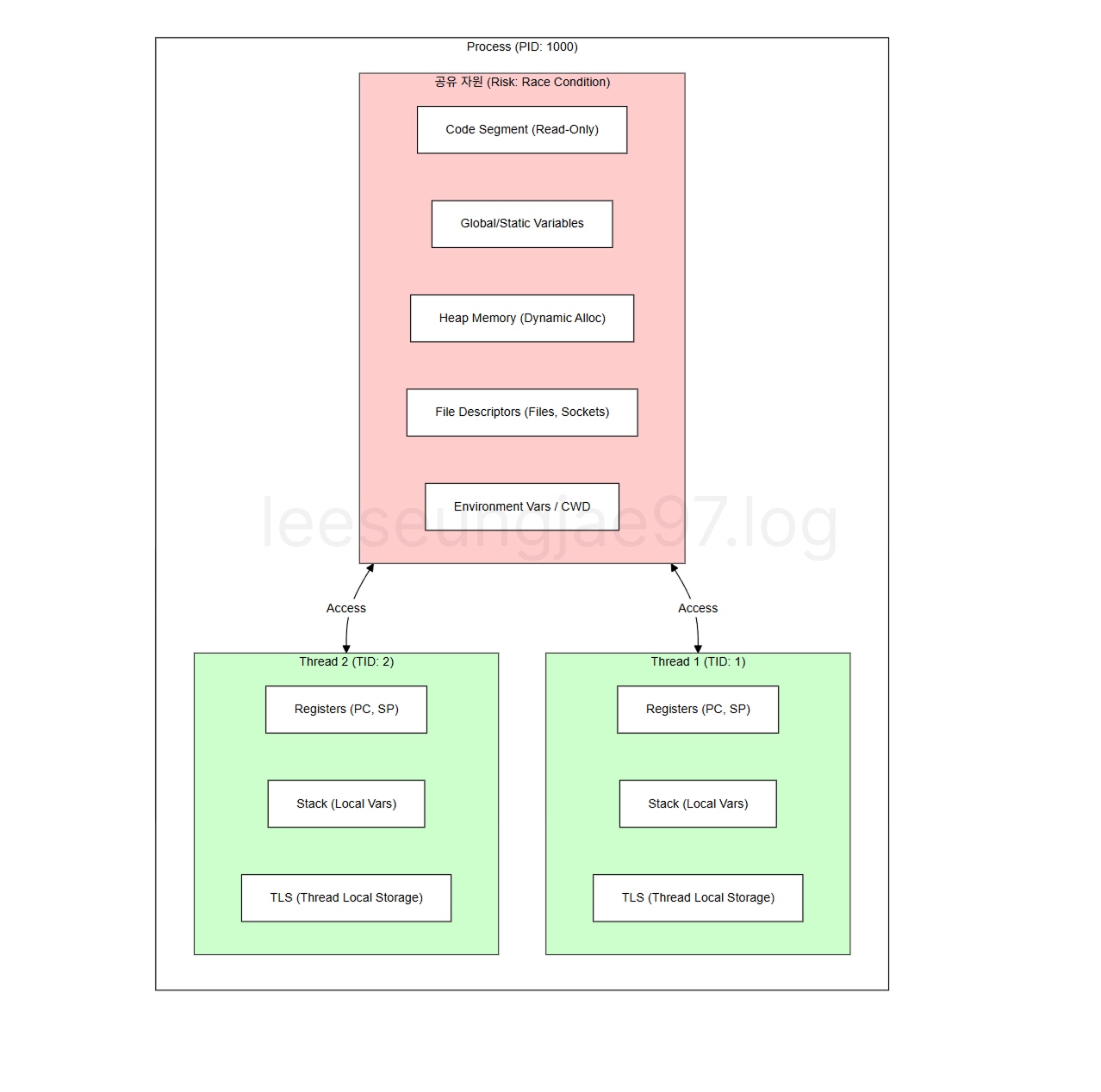
TLS, Stack
TLS : 스레드 전역 변수 영역으로
전역 변수의 편리함을 유지하면서도
스레드별 독립적인 저장 공간을 제공해서
동기화 없이 안전하게 스레드 고유 상태를 유지할 수 있다.
스레드별 랜덤 시드, 메모리 풀 등이 TLS에 만들어지면 사용이 편하다.Stack : 함수 호출마다 생기는 지역 변수, 함수가 끝나면 사라짐
비교 항목 Stack (스택) TLS (Thread Local Storage) 생명주기 (Lifecycle) 함수 범위 (Function Scope) 함수가 호출될 때 생성, 리턴하면 소멸 스레드 범위 (Thread Scope) 스레드 시작 시 생성, 종료 시 소멸 데이터의 성격 임시 변수 (지역 변수, 매개 변수, 리턴 주소) 스레드 전역 변수 (스레드 고유의 상태 값) 접근 범위 해당 함수 블록 { } 내부 해당 스레드 내의 모든 함수에서 접근 가능 할당 방식 컴파일러에 의해 자동 할당/해제 링커/로더 또는 API를 통해 할당 속도 매우 빠름 (CPU 레지스터 연산) 빠름 (하지만 포인터 참조/인덱싱 오버헤드 있음) 스레드 전체 LifeTime에 사용되는 변수이면서 스레드 독립적으로 사용하고 싶을 때 TLS 영역을 사용함.
| 비교 항목 | 사용자 수준 스레드 (ULT) | 커널 수준 스레드 (KLT) |
|---|---|---|
| 관리 주체 | 사용자 영역의 라이브러리 | 운영체제 커널 |
| 매핑 비율 | N : 1 (Many-to-One) | 1 : 1 (One-to-One) |
| Context Switching | 매우 빠름 (User Mode 내 처리) | 느림 (Kernel Mode 진입 필요) |
| Blocking 발생 시 | 프로세스 전체 중단 | 해당 스레드만 중단, 다른 스레드 실행 가능 |
| 멀티프로세서 활용 | 불가능 (한 번에 하나만 실행) | 가능 (병렬 처리) |
| 주요 예시 | Coroutine | 보편적 Thread |
아래는 상태를 저장하는 사용자 수준 스레드인 코루틴을 직접 구현함.
struct Task
{
int id;
int step = 0; // 프로그램 카운터(PC) 역할: 어디까지 실행했는지 저장
int local_var = 0; // 로컬 변수 상태 저장 (스택 역할)
bool run() {
switch (step) {
case 0:
local_var = 10;
step = 1; // 다음 실행 위치 저장
return true; // Yield (양보)
case 1:
local_var += 5;
step = 2; // 다음 실행 위치 저장
return true; // Yield (양보)
case 2:
step = -1; // 종료 상태
return false; // Done (완료)
}
return false;
}
};
int main()
{
// 스레드 2개 생성
vector<Task> tasks;
tasks.push_back({ 1 });
tasks.push_back({ 2 });
bool busy = true;
// 라운드 로빈 스케줄러
while (busy)
{
busy = false;
for (auto& t : tasks)
{
if (t.step != -1) // 종료되지 않은 스레드만 실행
{
bool keeping = t.run(); // 스레드 조금 실행하고 멈춤
if (keeping) busy = true; // 아직 할 일이 남았으면 스케줄러 계속 돔
}
}
// 스레드가 바뀌는 Context Swithcing
}
return 0;
}| 구분 | 프로세스 (Process) | 스레드 (Thread) |
|---|---|---|
| 메모리 | Code, Data, Heap, Stack 모두 독립적 | Code, Data, Heap 공유, Stack 및 Register만 독립적 |
| 통신 | IPC (Inter-Process Communication) 필요 (소켓, 파이프 등) | 공유 메모리(Heap, Global 변수)를 통해 직접 통신 |
| 비용 | 생성 및 Context Switching 비용이 큼 | 생성 및 Context Switching 비용이 적음 |
| 안전성 | 한 프로세스의 문제가 다른 프로세스에 영향 없음 | 한 스레드의 오류가 전체 프로세스 종료를 유발할 수 있음 |
프로세스는 PCB + 스레드 이다.
실제 CPU코어 위에서 명령어를 수행하는 주체는 스레드이다.
TCB(Thread Control Block)
PCB처럼 스레드도 Stack Pointer, PC, Register 값들을 저장한다.
OS 스케줄러가 실제로 스케줄링 하는 단위도 TCB이다.
멀티 스레드
하나의 프로세스 내에서 여러 개의 스레드를 동시에 돌리는 기법
멀티스레드는
- 멀티코어 CPU에서 동시에 실행 가능(병렬성)
- 구조적인 분리가 가능함(렌더링 스레드따로 물리 엔진따로)
- 자원 공유 비용이 감소함(IPC보다)
코어 하나당 하나의 스레드가 배정된다.
코어 개수를 초과 하는 스레드가 배정되면 병렬성과 동시성을 같이 사용하게 된다.
4코어 CPU가 있다고 가정할 때
1~4개의 스레드까지는 완전히 병렬적으로 실행된다.
하지만 4개가 넘어가는 순간부터 스레드를 교체해가며 사용하게 된다.
때문에 코어보다 많은 스레드를 사용하게되면 병렬처리로 얻는 이득보다
Context Switching 오버헤드가 더 커져서 성능이 떨어질 수 있음.
프로세스가 늘어난다고 코어를 여러개 쓰는게 아니라
스레드가 늘어나야 코어를 여러개 사용하는것이지만
프로세스는 하나 이상의 스레드를 가지고 있으니까
멀티 프로세스는 코어를 여러개 쓰고 병렬성이다 라고 말할수 있다.
다만 프로세스는 독립적인 메모리를 가지고 있고 그 외에
PCB, 가상 주소 공간 등의 역할을 가지고 있기 때문에(프로세스 격리라고 한다)
다른 프로세스들이 각각 스레드를 실행해도 관여하지 못하는 구조를 만들 수 있게 해준다.
Race Condition(경쟁 상태)
여러 실행 주체(스레드, 프로세스)가 공유 자원에 접근할 때
실행 순서에 따라 결과가 달라지는 상태
- 공유 데이터 존재 (전역 변수, 힙, 파일 등)
- 두 개 이상 스레드 동시 접근
- 원자적이지 않은 연산
- 동기화 부재
가 있을 때 발생한다.
int counter = 0; // 공유 자원
void Increment()
{
for (int i = 0; i < 100000; ++i)
{
counter++; // Race Condition 발생 지점
}
}
int main()
{
std::thread t1(Increment);
std::thread t2(Increment);
t1.join();
t2.join();
std::cout << "counter = " << counter << std::endl;
return 0;
}코드를 보면 공유 데이터가 존재하고, 임계 구역/영역(Critical Section)이 있으며, 원자적인 계산 없이 ++하고 있다.
첫번째 시도 : counter = 116173
두번째 시도 : counter = 170656
세번째 시도 : counter = 103303각 스레드가 10000씩 증가를 하기 때문에 20000을 예상하지만
실제로 20000이 나오지 않는다.
연산에는 일련의 과정(Load, Modify, Store)이 있기 때문인데,
- Load : counter 값을 메모리에서 읽음
- Modify : +1 연산
- Store : 결과를 메모리에 씀
두 스레드가 동시에 이 과정을 수행하면
같은 값을 읽고, 각각 +1 한 뒤, 같은 값으로 덮어쓰게 된다.
유실되는 증가가 발생 할 수 있다.
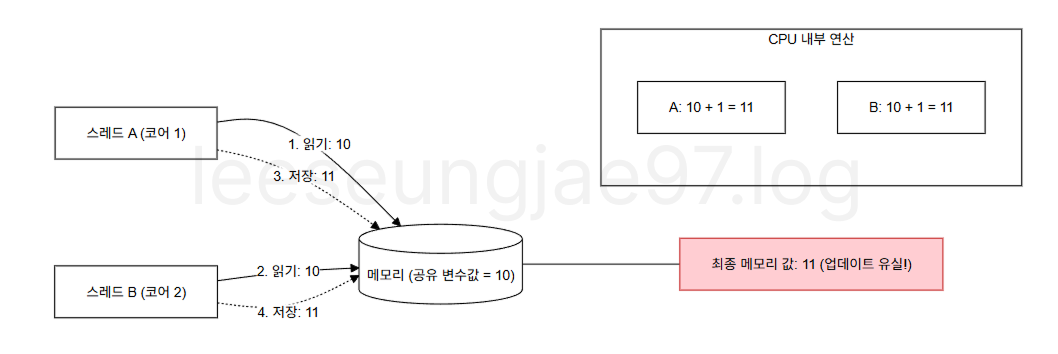
이러한 상황을 막기 위해 동기화 기법을 사용한다.
멀티코어 환경에서 Race condition
멀티코어 환경에서는 연산 과정뿐만 아니라,
L1/L2캐시 데이터가
메인 메모리와 동기화 되지 않아 다른 스레드가 업데이트된 값을
보지 못하는 문제도Race Condition의 원인이 된다.
False Sharing (거짓 공유)
CPU가 캐시라인을 통해 데이터를 가져와 사용할 때,
각기 다른 코어가 캐시라인 내부의 값을 변경하게 되면
코어가 캐시 라인이 오염되었다고 판정해 캐시라인이 무효화된다.
다시 메인 메모리에서 데이터를 읽어오는 과정이 반복되고,
CPU는 캐시를 비우고 채우고를 반복하게 됨.
패딩과 정렬을 통해 캐시라인안에 같은 공유자원이 없도록 해야한다.
struct SharedData
{
atomic<int> a;
long long dummy[8]; // 약 64바이트 정도 띄워줌
atomic<int> b;
};
>
struct SharedData
{
// 컴파일러에게 특정 바이트 단위 정렬 강제
alignas(64) atomic<int> a;
alignas(64) atomic<int> b;
};Mutex
Mutex (Mutual Exclusion, 상호 배제) 는
여러 스레드가 동시에 접근하면 안 되는 임계 구역을
한 번에 하나의 스레드만 접근하도록 보장하는 동기화 도구
// mutex
int counter = 0;
std::mutex m;
void Increment()
{
for (int i = 0; i < 100000; ++i)
{
m.lock();
// std::lock_guard<std::mutex> lock(m);
counter++;
m.unlock();
}
}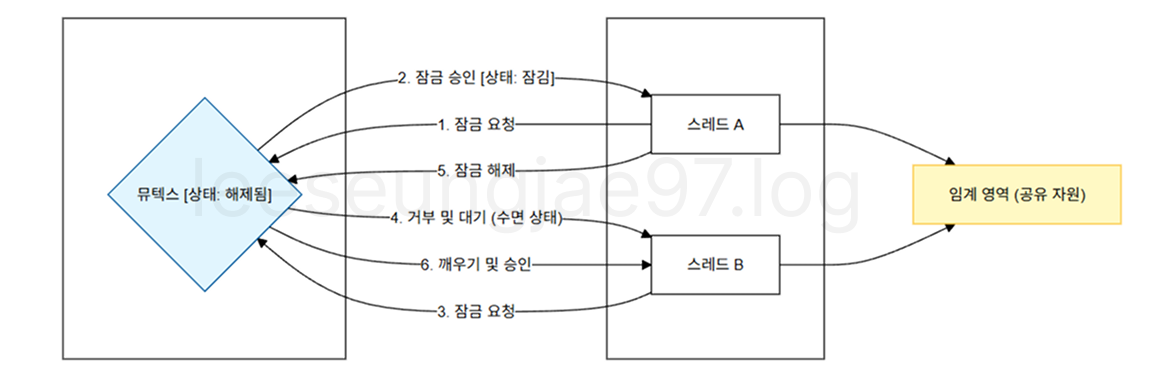
- 스레드 A가
lock()호출, Mutex 해제 - 즉시 획득, Mutex 잠금
- 스레드 B가
lock()호출, Mutex 잠금 - 거부 및 대기, Mutex 잠금
- 스레드 A가
unlock()호출, Mutex 해제 - 스레드 B의 대기를 풀고
lock(), Mutex 잠금
lock_guard와 직접lock, unlock차이
lock은 사용자가 직접unlock해줘야 한다.lock_guard는 구역을 벗어나면 자동unlockRAII구조를 사용함.RAII를 사용하냐 안하냐의 차이
Semaphore(Counting Semaphore)
공유 자원에 접근할 수 있는 스레드의 최대 허용 개수를 제어하는 동기화 도구
Mutex와 다르게 신호전달이 주 목적임.
std::counting_semaphore<3> sem(3); // 최대 3개 동시 허용
void worker(int id)
{
sem.acquire(); // wait()
// 임계 구역
sem.release(); // signal()
}| 비교 항목 | 뮤텍스 (Mutex) | 세마포어 (Semaphore) |
|---|---|---|
| 목적 | 상호 배제 (Locking) 임계 영역 보호 | 신호 전달 (Signaling) 자원 가용성 알림, 순서 제어 |
| 소유권 | 있음 (Owner 개념) Lock을 건 스레드만 Unlock 가능 | 없음 (Owner 개념 없음) 자원을 사용하지 않는 다른 스레드도 post() 가능 |
| 상태 | 이진 (Locked / Unlocked) | 정수 (0 이상) |
Binary Semaphore
Mutex와 동일하게 작동하지만
Semaphore는 acquire 하지 않은 스레드가 release() 를 호출 할 수 있음
binary_semaphore ready(0);
void worker()
{
ready.acquire(); // 신호 대기
do_work();
}
void controller()
{
prepare();
ready.release(); // 신호 전달
}생산 스레드는 release만하고 소비 스레드는 acquire만 한다.
이런 개념에 Mutex를 쓰게 되면 논리적으로 애매하다.
생산 스레드가 lock을 하고 소비 스레드가 unlock을 한다고 생각해보자.
생산 스레드가 unlock을 해줘야 소비 스레드가 lock을 할 수 있고
애초에 생산 스레드의 lock을 소비 스레드가 unlock할 수 있는 방법이 없다.
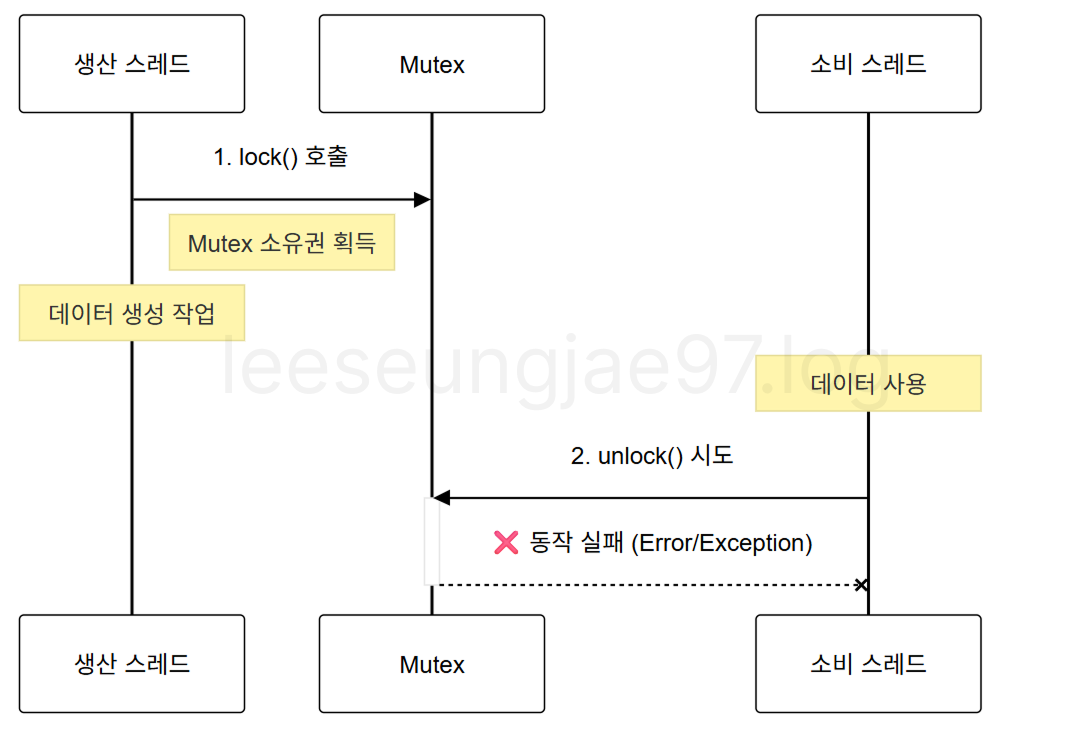
아니면 생산 스레드가 lock을 하고 소비 스레드가 lock을 요청하며 기다린다고 생각해보자.
생산 스레드가 생산 작업이 끝나면 unlock을 해 소비 스레드가 lock을 하고 자원을 획득한다.
소비 스레드가 다시 unlock하고 나면 생산 스레드가 다시 lock을 해 생산 작업을 진행한다.
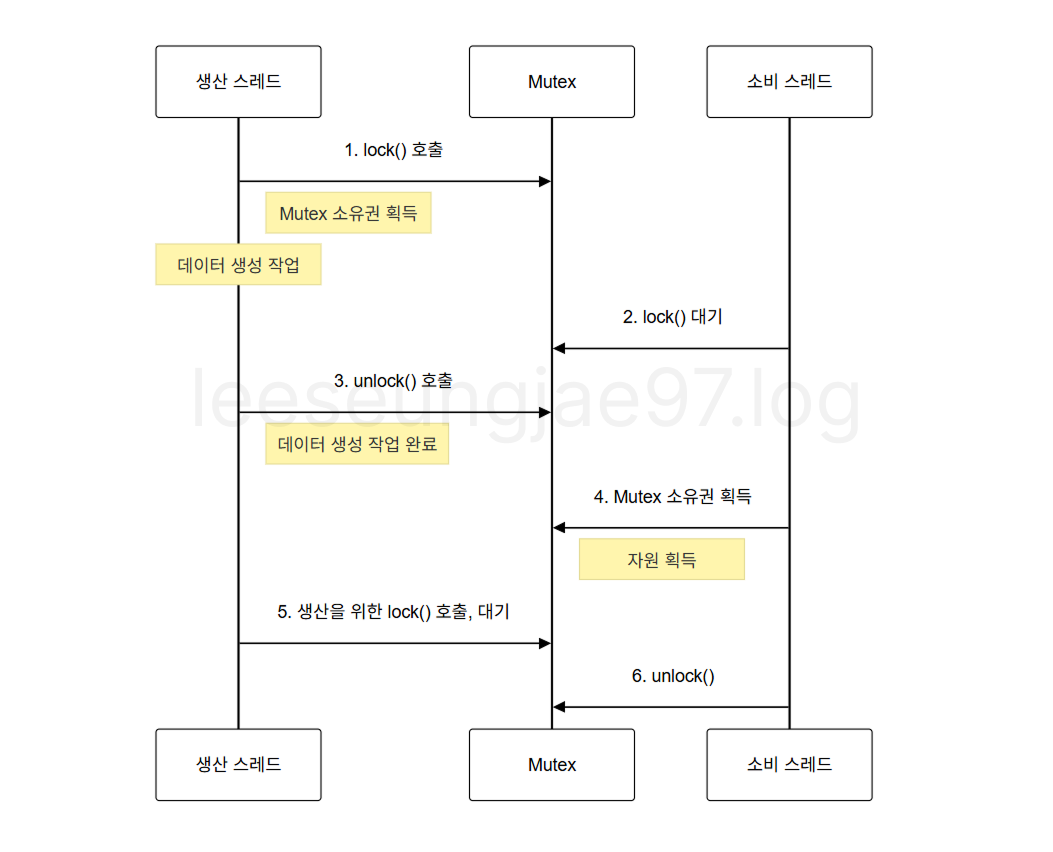
이렇게 하게되면 Spinlock이 발생한다는 단점이 있다.
이런 경우 Binary Semaphore를 사용하면 해결된다.
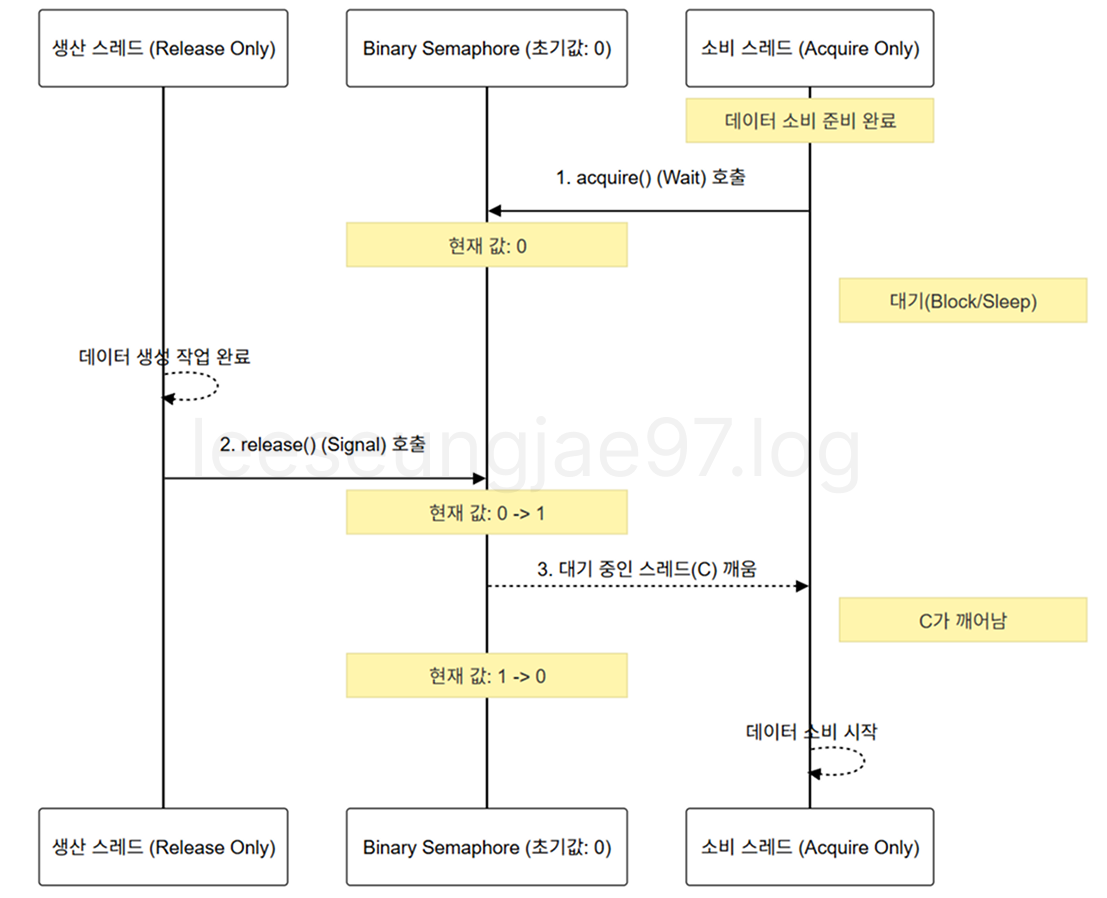
소비 스레드는 acquire만 하고, 생산 스레드는 release만 한다.
역할에 따라 구분되어 Spinlock이 발생하지 않는다.
소비 스레드는 acquire를 하고 잠드니까 코어를 사용하지 않고
생산 스레드가 생산 작업이 끝나면 release를 호출 해 소비 스레드가 깨어난다.
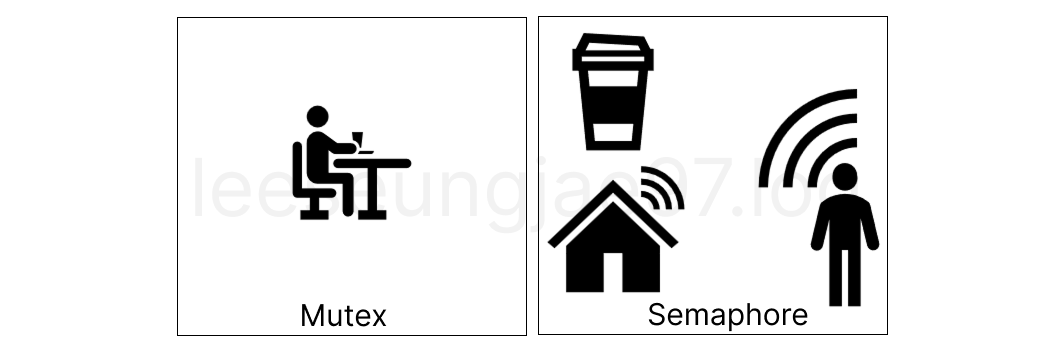
Mutex로 만들면 가게가서 커피를 시키고 가게에서 기다리는거고
Binary Semaphore로 만들면서 앱으로 주문하고 테이크 아웃 해가는 것이다.
다만 Binary라는게 0과 1만 사용하기 때문에
생산 스레드가 여러개인 모델에는 사용할 수 없다.
그럼 나중의 확장성을 위해서라도
카운팅 세마포어로 구현하면 되는거 아닌가?
맞다, Binary Semaphore는 의미적인(한번 발생하는 이벤트) 부분에 적합할 때 사용된다
결국 Binary와 Counting은 성능차이가 아닌 의미적인 차이로 나뉜다
Monitor + Condition variable
Monitor : 공유 상태 + 상호 배제 + 조건 대기가 묶인 동기화 구조 아래코드에서는
조건 상태(bool값, 코드에서는 queue) + Mutex + condition_variable가 각각 그 역할을 한다.
Condition variable : 특정 조건에 실행 순서를 제어할 수 있음.
wait(): 프로세스/스레드의 상태를 대기 상태로 전환notify_one()/signal()실행 상태로 재개
template <typename T>
class SafeQueue
{
private:
queue<T> q;
mutex mtx;
condition_variable cv;
public:
void push(T value)
{
unique_lock<mutex> lock(mtx);
q.push(value);
cv.notify_one();
}
T pop()
{
unique_lock<mutex> lock(mtx);
while (q.empty())
{
cv.wait(lock);
}
T value = q.front();
q.pop();
return value;
}
};
int main()
{
SafeQueue<int> sq;
thread consumerThread([&]()
{
int val = sq.pop();
cout << "Consumer popped: " << val << endl;
});
thread producerThread([&]()
{
this_thread::sleep_for(chrono::milliseconds(100));
cout << "Producer pushing: 10" << endl;
sq.push(10);
});
consumerThread.join();
producerThread.join();
return 0;
}Monitor
class SafeQueue
{
private:
queue<T> q; // 공유 데이터
mutex mtx; // 상호 배제
condition_variable cv; // 조건 대기
...
public:
void push(...); // monitor entry
T pop(); // monitor entry
}Condition variable 사용
cv.wait(); // 조건 까지 대기
...
cv.notify_one();// 조건 변경 알림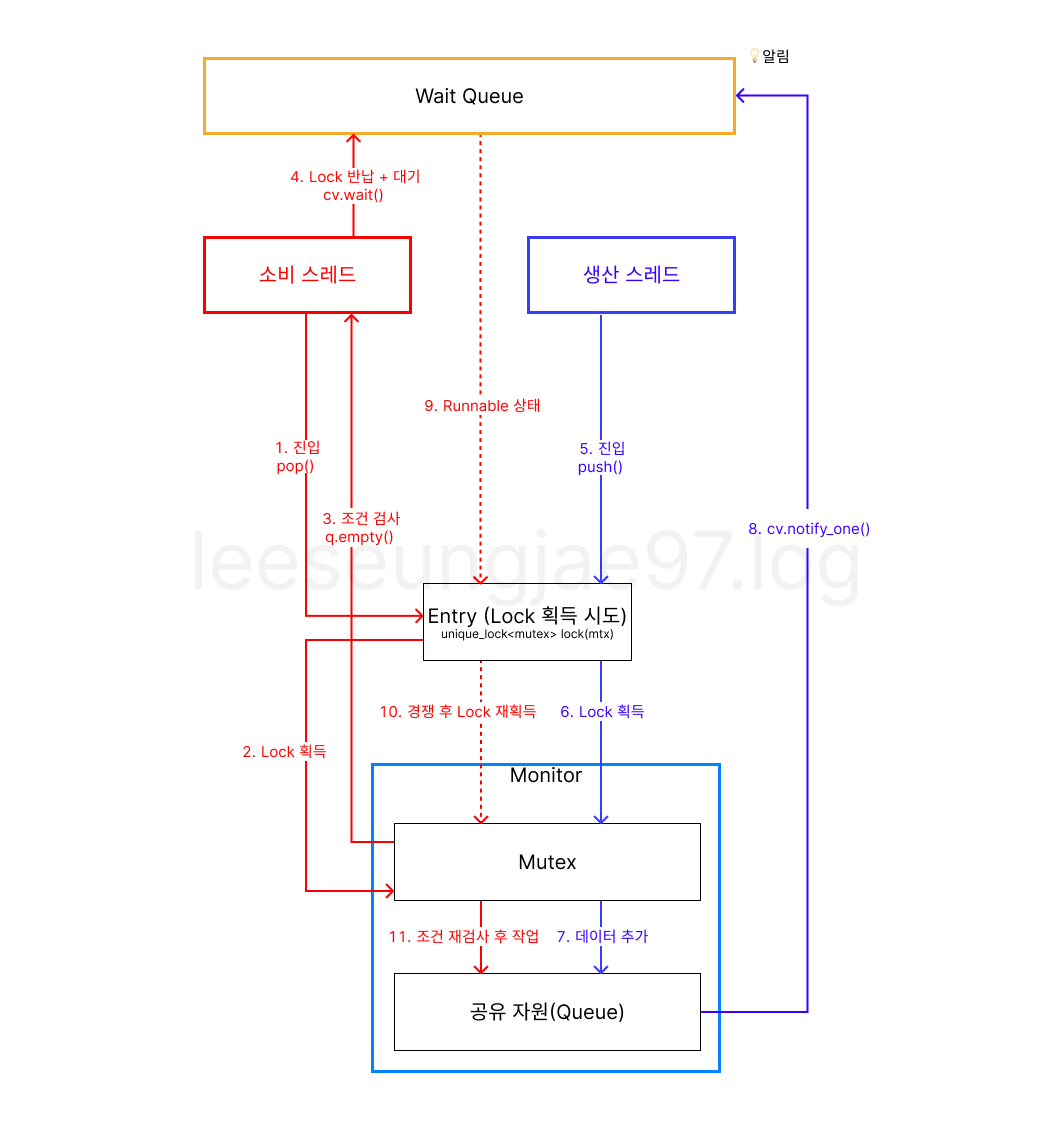
Atomic 타입
연산을 쪼개지지 않고 다른 스레드에서 중간 상태를 관찰할 수 없게 한다.
일반적인 변수 연산은 Load → Modify → Store 3단계로 나뉘어 작동한다.
counter++;
// 단일 연산은 세 단계로 분해된다.
int counter = 0; // Load
tmp = tmp + 1; // Modify
counter = tmp; // Store CPU가 레지스터에서 계산을 수행하기 때문에 이런 현상이 발생한다.
메모리 → 레지스터 → 연산 → 메모리 단계가 나뉘어져 있기 때문에 Race condition이 발생한다.
| 시점 | Thread A | Thread B |
|---|---|---|
| 1 | Load x → 0 | |
| 2 | Load x → 0 | |
| 3 | Modify → 1 | |
| 4 | Modify → 1 | |
| 5 | Store → x = 1 | |
| 6 | Store → x = 1 |
atomic은 CPU 명령어를 사용해, Load(메모리 → 레지스터) + Modify + Store(레지스터 → 메모리)을 하나의 Modify, 원자적 명령으로 만든다.
atomic<int> x = 10;
int x2 = 11;
x += 10; // fetch_add(10)와 동일하게 작동함
x2 += 10;
x = x + 10; // 이건 atomic 연산이 Overloading되어 있지 않다. 66: atomic<int> x = 10;
mov edx,0Ah
lea rcx,[x]
call std::atomic<int>::atomic<int>
67: int x2 = 11;
mov dword ptr [x2],0Bh
69: x += 10;
mov edx,0Ah // 더할 값 10
lea rcx,[x] // atomic 객체 주소
call
// 내부에서 Load + Modify + Store
std::_Atomic_integral_facade<int>::operator+=
// atomic이 아닌 x2의 연산과정
70: x2 += 10;
mov eax,dword ptr [x2] // Load
add eax,0Ah // Modify
mov dword ptr [x2],eax // Store
// atomic이지만 원자적 연산을 하지 않음.
13: x = x + 10;
lea rcx,[x]
call std::atomic<int>::operator int // 원자적 Load
add eax,0Ah // Modify
mov edx,eax
lea rcx,[x]
call std::atomic<int>::operator= // 원자적 Store
// operator+와 operator=를 쓰고 있어서 그렇다.
// +=와 동일
14: x.fetch_add(10);
mov r8d,5
mov edx,0Ah
lea rcx,[x]
call std::_Atomic_integral<int,4>::fetch_add (07FF71D6815C8h)atomic은 operator+=, operator-=, operator++, operator--를 오버로딩 해 두었다.atomic에서 제공하는 함수를 쓰는게 코드 가독성도 높이고 의미전달도 잘 된다.
memory order
현대 CPU는 성능 최적화를 위해 명령어의 순서를 바꾼다.
int a = 1, b = 1;
void func()
{
// CPU가 최적화를 위해 아래 둘의
// 연산 순서를 바꿀 수 있음.
a = b + 1;
b = 1;
}atomic은 단순히 값이 찢어지는 걸 막는 것을 넘어,memory_order를 통해 명령어의 실행 순서를 강제하는
메모리 베리어 역할도 수행한다.
memory_order_release : 해당 명령 이전의 모든 메모리 명령들이,
해당 명령 이후로 재배치 되는 걸 금지.
memory_order_acquire : 해당 명령 뒤에 오는 모든 메모리 명령들이,
해당 명령 위로 재배치 되는 걸 금지.
아래 코드는 memory order를 이용해 소비-생산 패턴에서 동기화를 수행한다.
atomic<bool> ready;
void producer()
{
{
lock_guard<mutex> lock(m);
sharedData = 42;
}
// data 담는중...
ready.store(true, memory_order_release);
}
void consumer()
{
// data가 준비 될 때 까지 기다림
while (!ready.load(memory_order_acquire))
{
// ...
}
lock_guard<mutex> lock(m);
}atomic은 중간 상태를 없애서 값의 찢어짐만 막을 뿐
행위의 순서나 의사 결정의 일관성은 보장하지 않는다.
결국 위 코드도 하나의 코어를 100% 점유하며 계속 확인한다(Busy waiting, Spinlock).
복합적인 불변식이나 논리적 동기화에는 Mutex와 같은 고수준 동기화가 필요하다.
DeadLock(교착 상태)
Race Condition을 막기 위해 동기화를 도입했을 때 발생하는
두 개 이상의 실행 주체가 서로가 가진 자원을 기다리며
영원히 진행하지 못하는 상태
- Mutual Exclusion (상호 배제), 자원을 동시에 공유 불가하고
- Hold and Wait, 자원을 잡은 채 다른 자원을 기다리고
- No Preemption, 자원을 강제로 빼앗을 수 없고
- Circular Wait, 자원 요청이 순환 구조일 때
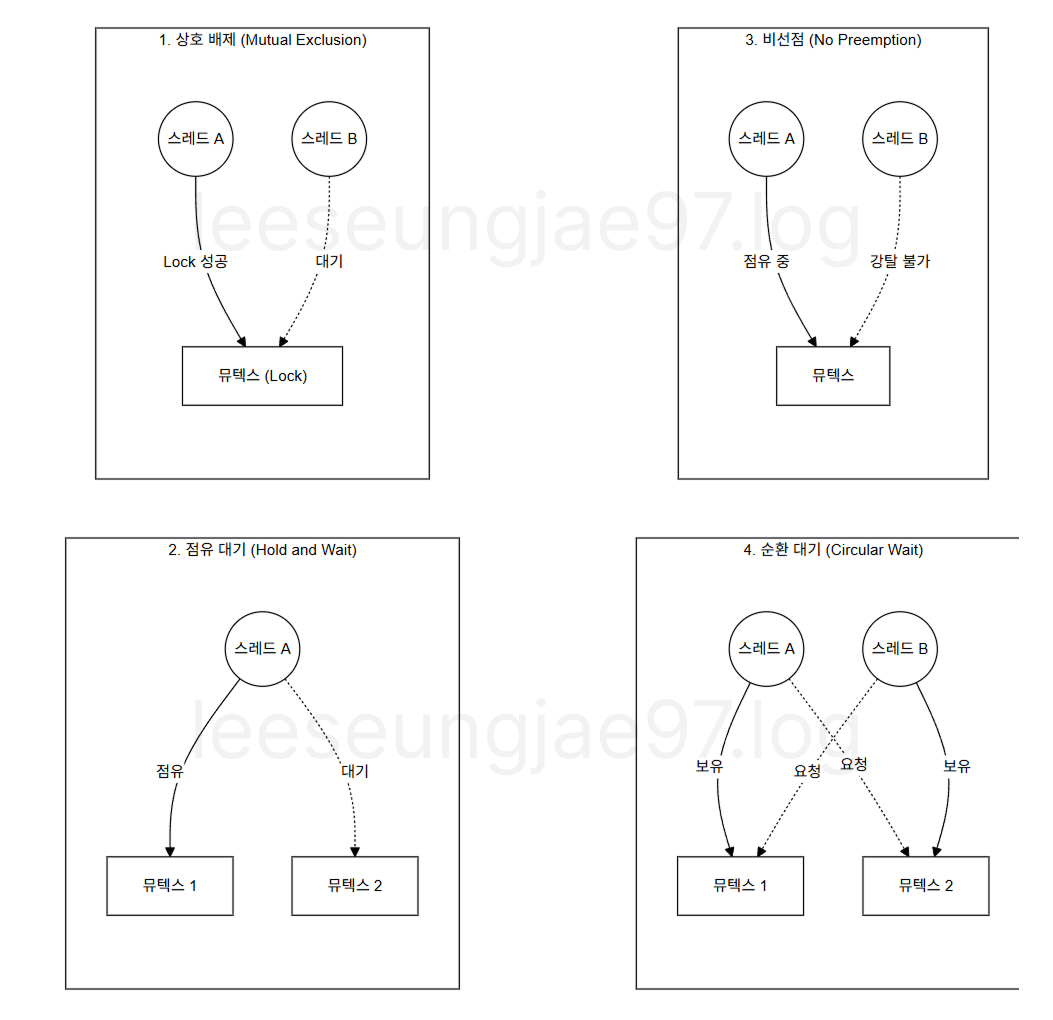
발생한다.
해결방법 (모던 C++ 내용제외)
Lock 순서 고정
void funcA() { MutexA.lock(); MutexB.lock(); } void funcB() { // funcA에서 하던 lock 순서와 다름 MutexB.lock(); MutexA.lock(); } // 순환 대기할 위험이 있음.
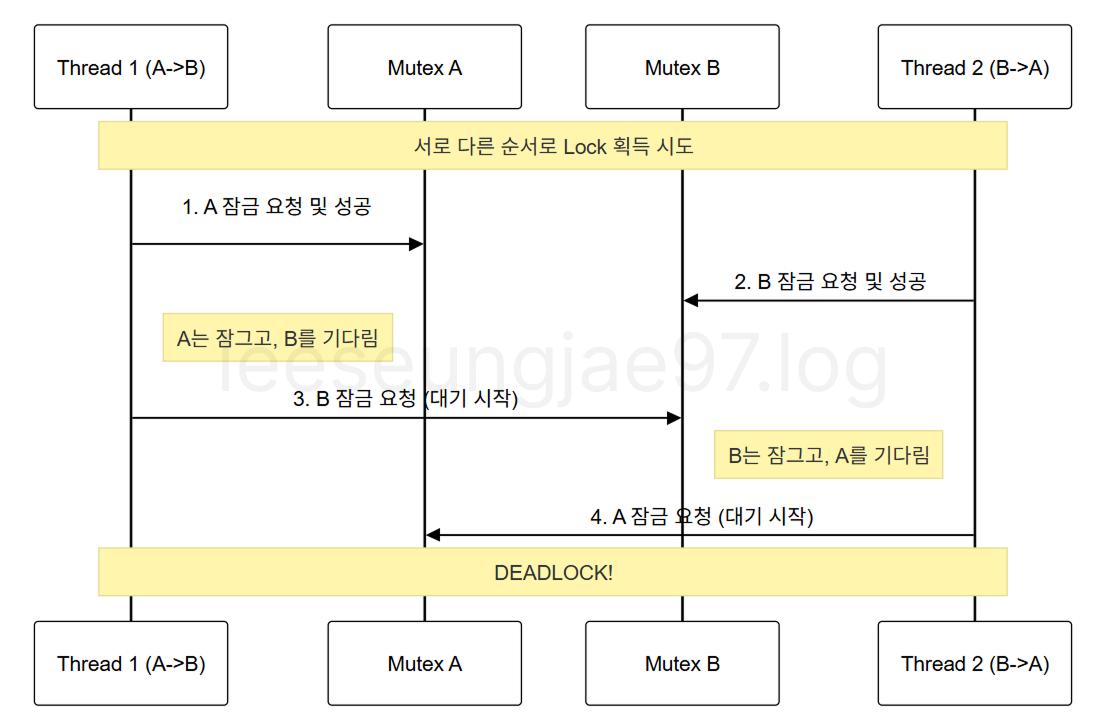
// 항상 lock 순서는 똑같게.
void funcA()
{
MutexA.lock();
MutexB.lock();
}
void funcB()
{
MutexA.lock();
MutexB.lock();
}try lock
void safe_func() { while (true) { if (A.try_lock()) { if (B.try_lock()) { // critical section B.unlock(); A.unlock(); break; } A.unlock(); } std::this_thread::yield(); // backoff } }
> yield
> 락을 해제하지 않고 잠들지 않음
> 계속 CPU 사용하지만 다른 스레드에 사용을 양보함.
> 조건 대기일 때 큐 사용없이 스레드를 대기시킬 수 있음
이 외에 Deadlock 조건을 회피 할 수 있으면 파훼 가능.
---
## LiveLock
보통 데드락을 회피하기 위한 로직에 의해 발생한다. 서로의 상태를 변화시키느라
실제적인 작업을 수행하지 못하는 상태를 말한다.
```cpp
void do_work(Resource& a, Resource& b)
{
while (true)
{
a.lock();
if (!b.try_lock()) // B를 못 잡으면
{
a.unlock(); // 데드락 방지를 위해 A를 포기하고
continue; // 처음부터 다시 (반복)
}
// 임계 구역 작업
break;
}
}해결 방법으로 지연시간을 랜덤화하고 기다리면서 타이밍이 어긋나게 한거나,
스레드에 우선순위를 두어 충돌 시 특정 스레드가 자원을 먼저 선점하게 규칙을 정해 해결할 수 있다.
스레드는 프로세스 내에서 자원을 공유하며 실행되는 최소 작업 단위로, 멀티코어 환경에서 병렬성을 통해 성능을 높일 수 있지만,
공유 자원에 대한 경쟁 상태(Race Condition)를 막기 위해 뮤텍스, 세마포어, 원자적 연산(Atomic) 등의
적절한 동기화 기법과 데드락/라이브락에 대한 설계가 필요한 실행 흐름이다.
문제
20문제
https://gemini.google.com/share/3c0dce994c0f
틀린 부분 알려주시면 저에게 큰 도움이 됩니다. 읽어주셔서 감사합니다.