메모리 계층 구조
| 계층 | 위치 | 기술 기반 | 접근 속도 | 용량 | 휘발성 | 관리주체 |
|---|---|---|---|---|---|---|
| Register | CPU Core 내부 | Flip-Flop | < 1 cycle (즉시) | 수백 Bytes ~ 수 KB | O | 컴파일러 / HW |
| L1 Cache | CPU Core 내부 | SRAM | 1 ~ 4 cycles | 32KB ~ 512KB | O | 하드웨어 |
| L2 Cache | CPU Core 내부/인접 | SRAM | 10 ~ 20 cycles | 256KB ~ 2MB | O | 하드웨어 |
| L3 Cache | CPU Shared (공유) | SRAM | 40 ~ 75 cycles | 8MB ~ 128MB+ | O | 하드웨어 |
| Main Memory | CPU 외부 (DIMM) | DRAM | 200 ~ 400 cycles | 8GB ~ 128GB+ | O | OS / 하드웨어 |
| Storage (SSD) | I/O Bus | NAND Flash | 수만 cycles (μs 단위) | 256GB ~ 수 TB | X | OS / 파일시스 |
| Storage (HDD) | I/O Bus | Magnetic Disk | 수백만 cycles (ms 단위) | 1TB ~ 20TB+ | X | OS / 파일시스 |
레지스터
CPU가 직접 접근하고 제어하는, CPU 내부의 초고속 임시 저장 장치이다.
CPU 내부에 존재하는 가장 작은 저장 공간으로, CPU 칩 내부 ALU와 제어장치 옆에 있다.
컴퓨터 구성 요소 중 가장 빠른 장치로 속도가 CPU클럭과 같다.
메인 메모리(RAM)보다 훨씬 빠르지만 용량이 매우 작다.
연산에 필요한 데이터와 명령어의 주소를 일시적으로 보관한다.
주요 레지스터
| 레지스터 명칭 | 약자 | 주요 역할 | 사용되는 곳 |
|---|---|---|---|
| 프로그램 카운터 | PC | 다음에 실행할 명령어의 주소 저장 | 명령어 인출(Fetch)의 시작점 |
| 명령어 레지스터 | IR | 메모리에서 가져온 명령어 자체를 저장 | 제어장치의 명령어 해석(Decode) 단계 |
| 메모리 주소 레지스터 | MAR | CPU가 접근하려는 메모리의 주소를 보관 | 주소 버스로 주소를 쏘기 직전 |
| 메모리 버퍼 레지스터 | MBR | 메모리와 주고받는 실제 데이터를 저장 | 데이터 버스와의 통로 역할 |
| 누산기 | AC | 연산의 중간 결과물을 임시로 저장 | ALU의 연산 과정 |
| 범용 레지스터 | GPR | 데이터나 주소를 가리지 않고 자유롭게 사용 | 프로그래머가 작성한 어셈블리 명령 수행 시 |
| 플래그 레지스터 | FR | 연산 결과의 상태(양수/음수,0 여부/오버플로)를 저장 | 조건문(if)이나 루프 제어 시 |
A = B + C라는 연산이 일어날 때, 일련의 과정CU는 제어장치, ALU는 산술연산장치
→ CU가 PC가 가리키는 주소를 MAR에 보냄
→ CU가 메모리에서 명령어를 가져와 → MBR을 거쳐 IR에 저장 (인출)
→ CU가 IR을 통해 더하기연산 이라고 해석 (해석)
→ CU가 데이터 B와 C를 메모리에서 가져와 CU가 GPR에 둔다
→ CU가 ALU으로 두 값을 더하게 하고 그 결과를 →CU가 AC(누산기)에 저장 (실행)
→ ALU가 계산 중 발생한 상태를 CU가 FR에 기록
캐시 메모리(SRAM)
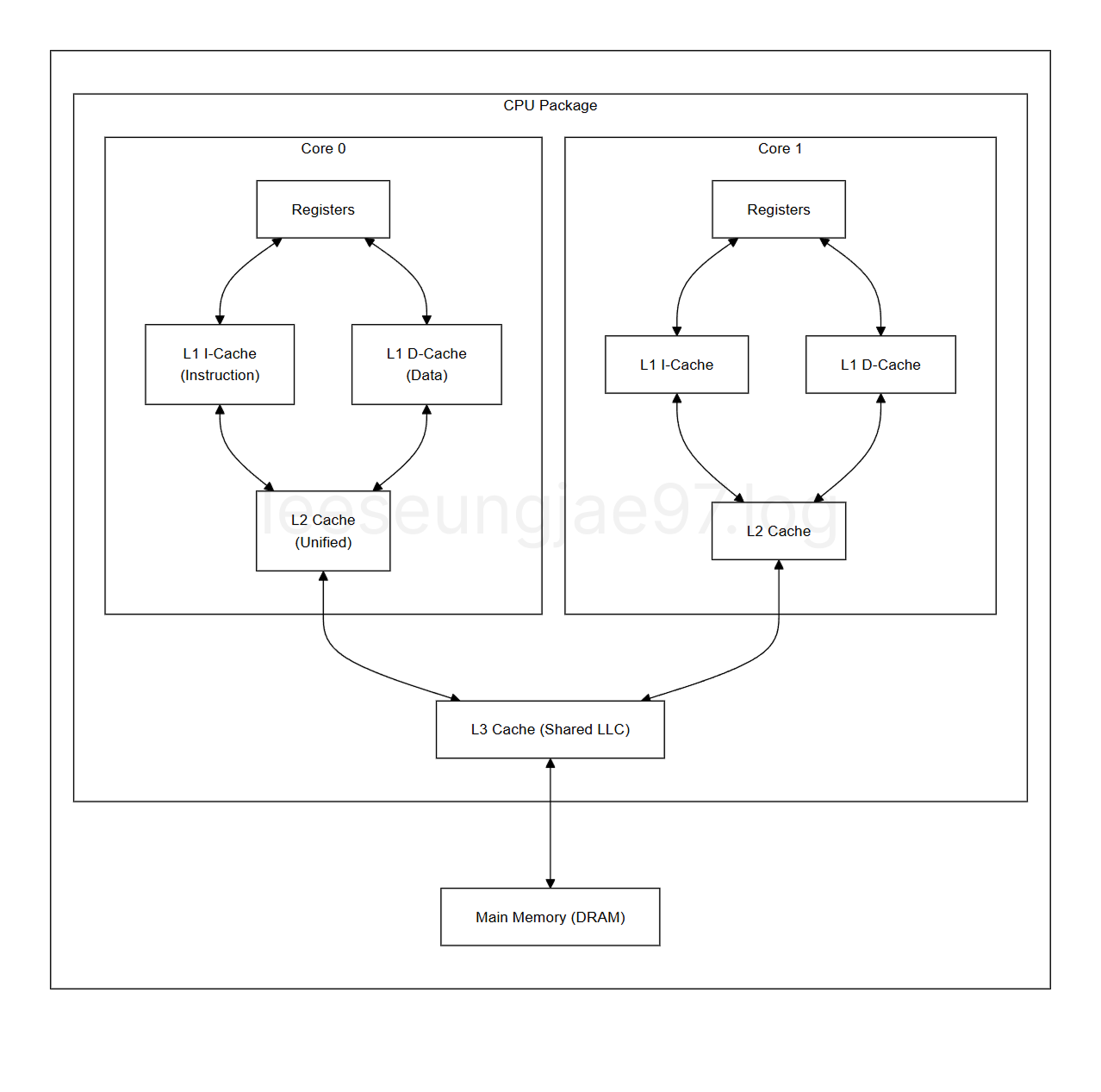
CPU옆에 있는 고속 임시 메모리, CPU와 RAM사이의 속도 차이 완화한다.
재참조 가능성이 높은 데이터를 보관하고 유지한다.
데이터 교체 주기와 알고리즘이 존재함.
- 시간적 지역성 : 한번 참조된 데이터
- 공간적 지역성 : 참조된 데이터 인접 주소 데이터
L1 Cache
- CPU 코어 바로 옆에 내장된 매우 빠른 메모리.
- CPU 코어당 전용으로 존재.
- CPU가 자주 사용하는 데이터를 레지스터로 올리기 전에 임시로 보관, 메인 메모리까지 가는 시간을 줄임.
- 명령어 캐시와 데이터 캐시로 분리
L2 Cache
- CPU 코어당 전용 또는 CPU 다이 내에 공유
- L1 캐시에서 찾지 못한 데이터를 빠르게 제공
L3 Cache
- 멀티코어 CPU에서 여러 코어가 공유
- CPU 다이 내부에 존재, 모든 코어가 공유
- 여러 코어가 공유하는 데이터를 보관하여 데이터 일관성을 유지
- L2 캐시 미스를 보완하여 메인 메모리 접근을 최소화
캐시 메모리가 빠른 이유는 작고, 전력 많이 써도 되는 특별한 메모리이기 때문이라서,
그걸 전체 메모리 크기로 확장하면 그 속도가 나오지 않음.
캐시히트, 캐시미스
캐시 메모리는 메모리의 일부중 CPU가 사용할 법한 것을 예측해 복사하여 저장한다.
저장한 데이터를 사용한다면 캐시히트,
캐시에 데이터가 없어서 메모리로 접근해야되는 경우를 캐시미스라고 한다.
캐시 메모리는 참조 지역성의 원리 원칙에 따라 메모리로부터 가져올 데이터를 결정
- 시간 지역성 : CPU가 최근 접근했던 메모리 공간
- 공간 지역성 : CPU가 접근한 메모리 근처 공간
vector<vector<int>> arr(10000, vector<int>(10000));
CLOCK_INIT;
CLOCK_START;
for (int i = 0; i < arr.size(); ++i)
{
for (int j = 0; j < arr[i].size(); ++j)
{
// col major로 읽기
// [0][0] - [1][0] - [2][0]
arr[j][i] = 1;
}
}
CLOCK_END;
CLOCK_START;
for (int i = 0; i < arr.size(); ++i)
{
for (int j = 0; j < arr[i].size(); ++j)
{
// row major로 읽기
// [0][0] - [0][1] - [0][2]
arr[i][j] = 0;
}
}
CLOCK_END;결과
Col Major TIME : 1948 ms
Row Major TIME : 1356 msCPU는 캐시 라인이라는 데이터를 가져오는 최소 단위를 쓴다.
이 단위는 보통 64바이트 이다.
그래서 arr[i][j]와 arr[i][j+1]이 붙어 있을 때 j를 먼저 읽으면
한 번의 메모리 접근으로 뒤의 데이터까지 캐시 라인 단위로 들어온다.
지연쓰기, 즉시쓰기
지연쓰기 : CPU가 데이터를 캐시에 쓰면, 일단 캐시에만 반영하고 나중에 한번에 바꿈
즉시쓰기 : CPU가 데이터를 캐시에 쓰면 메인 메모리에 즉시반영
| 특징 | 지연 쓰기 (Write-Back) | 즉시 쓰기 (Write-Through) |
|---|---|---|
| 메모리 반영 시점 | 캐시 교체 시 또는 명시적 플러시 시 | 캐시 쓰기와 동시에 |
| 쓰기 성능 | 빠름 (CPU는 캐시에만 쓰고 즉시 다음 작업) | 느림 (메인 메모리 쓰기 완료까지 대기) |
| 데이터 일관성 | 복잡하게 관리 (수정 비트, 관리 프로토콜 사용, 그럼에도 일관성이 깨질 수 있는 위험 있음) | 단순하게 유지 (캐시 = 메인 메모리) |
| 메모리 대역폭 | 절약 (같은 데이터 여러 번 수정 시 한 번만 반영) | 낭비 (같은 데이터 여러 번 수정 시 매번 반영) |
| 데이터 손실 위험 | 높음 (Dirty 데이터가 메인 메모리에 미반영 상태) | 낮음 |
| 하드웨어 복잡성 | 높음 (Dirty Bit, 일관성 프로토콜) | 낮음 (Write Buffer만으로 완화 가능) |
| 주요 사용처 | L1, L2, L3 캐시 (속도 중요) | Write Buffer와 함께 사용될 때, 또는 더 낮은 레벨 캐시나 특정 시스템 |
메인 메모리(Dynamic Random Access Memory)
- 데이터를 실제로 저장하는 하드웨어
- 현재 실행 중인 프로그램이나 OS 일부분, CPU가 처리할 데이터를 저장
- 보조 저장 장치로부터 데이터를 로드, CPU가 처리할 수 있도록 준비하는 역할
- 캐시 메모리가 CPU와 메인 메모리 사이의 속도 차이를 완화
- 프로세스를 여러 페이지로 나누어 분산 적재함(페이징)
메모리 단편화
- 외부 단편화 : 총 여유 공간은 충분하지만, 연속된 공간이 없음.
- 내부 단편화 : 할당된 공간이 사용하는 양보다 커서 낭비되는 공간.
가상 메모리
프로세스에 제공되는 논리적 주소 공간
보조 저장 장치의 일부를 메인 메모리처럼 사용한다.
가상 메모리에 저장된 프로그램을 실행하려면 물리 메모리의
주소로 바꾸는 주소 변환 작업이 필요하다.
가상 주소를 물리주소로 변환하는 과정에서 페이지 테이블을 매번 참조하면
메인 메모리에서 두번 접근(테이블 확은 + 데이터 확인) 해야한다.
이를 위해 최근 사용된 페이지 매핑 정보를 저장하는 고속 캐시인TLB(Translate Lookaside Buffer)가 CPU 내부에 존재한다.
- 디스크 Swap을 통해 물리 메모리 보다 큰 프로그램 실행 가능
- 프로스세마다 독립된 가상 주소 공간을 가짐
- 공통으로 사용하는 라이브러리는 물리 메모리에 한번만 올리고 공유 가능
- 물리 메모리가 파편화 되어도 논리적으로 연속된 주소 공간을 제공
가상 주소 공간은 연속적이지만, 실제 물리 주소는 불연속적이고 일부는 디스크에 있을 수 있음.
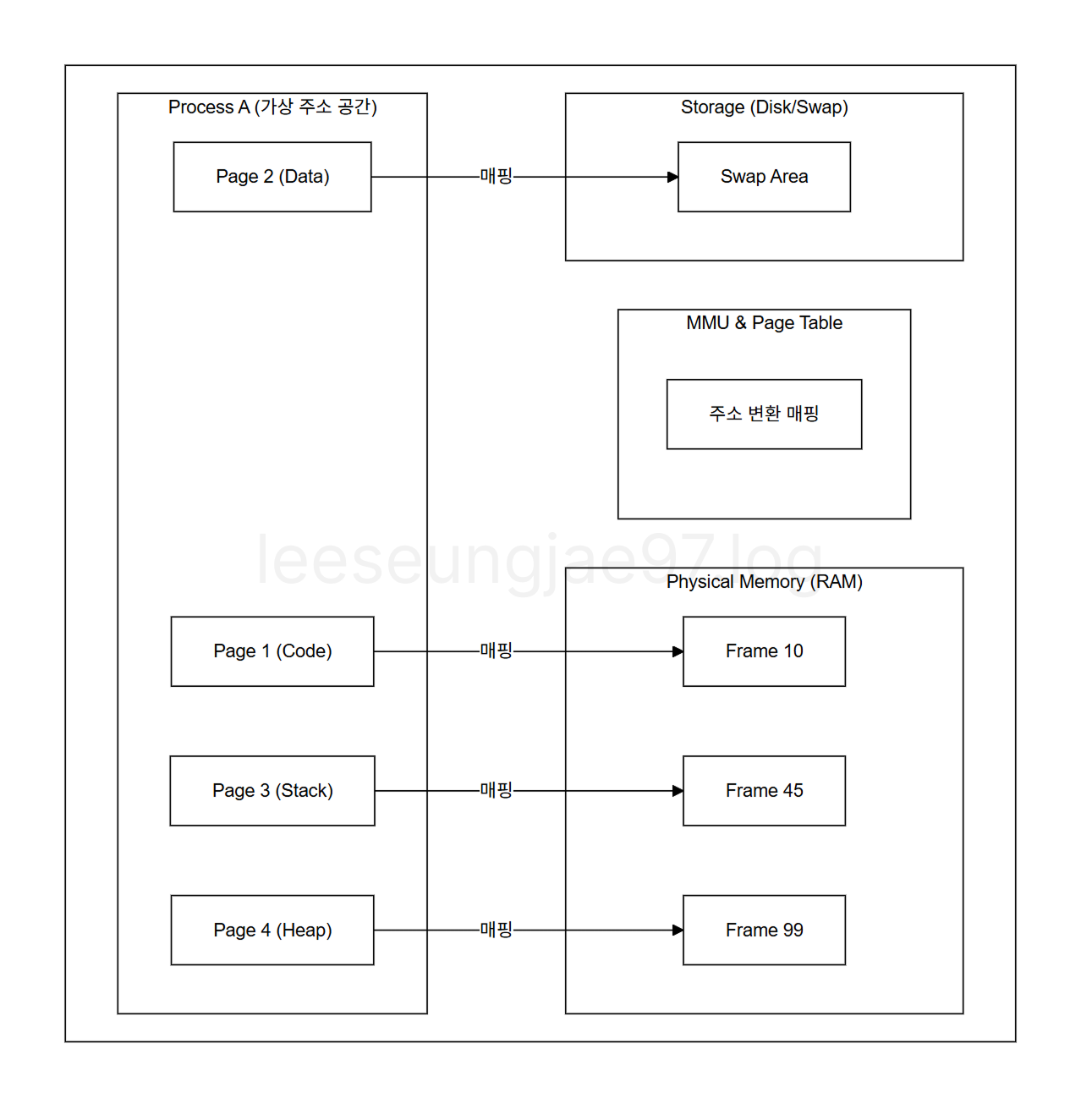
이 경우 Page2에 접근하게 되면 Page Fault 유발
가상 메모리 적재 기법
페이징
가상 메모리와 물리 메모리를 고정 크기로 분할 관리하는 기법
- 페이지 : 가상 메모리를 나눈 고정 크기 블럭
- 프레임 : 물리 메모리를 나눈 동일한 크기 블럭
- 페이지 맵 테이블 : 페이지가 어떤 프레임에 저장되어 있는지 기록해둔 매핑 테이블
페이징은 외부 단편화를 제거하지만, 페이지 크기만큼의 내부 단편화 발생할 수 있음.
프로세스의 크기가 고정 크기 블럭인 페이지로 나누기 때문이다.
페이지 크기의 배수가 아닐 때 마지막 페이지에는 남는 공간이 생긴다.
- 페이지 테이블의 구성 엔트리가 유효하지 않으면 페이지 폴트가 발생
- 페이지 테이블이 적재된 위치를 레지스터인
PTBR(Page Table Base Register)에 적재함
세그먼테이션
보조 저장 장치에 보관되어 있는 프로그램을 다양한 크기의
논리적인 단위로 나눈 후 메인 메모리에 적재시켜 실행하는 방법
- 프로그램을 세그먼트로 나누어 관리
- 세그먼트 맵 테이블을 통해 접근해 사용
- 가변크기의 블록을 사용해 필요한 만큼만 할당
- 세그먼트 크기가 달라 할당과 해제를 반복하면 외부 단편화를 발생시킬 수 있음.
- 가변 크기 블록 배치하는 알고리즘이 필요함.
| 특징 | 페이징 (Paging) | 세그먼테이션 (Segmentation) |
|---|---|---|
| 할당 단위 | 고정 크기 (Page) | 가변 크기 (Logical Unit) |
| 메모리 뷰 | 물리적 관점 (기계 친화적) | 논리적 관점 (사용자/개발자 친화적) |
| 단편화 | 내부 단편화 발생 | 외부 단편화 발생 |
| 공유/보호 | 복잡함 (페이지 경계 고려 필요) | 용이함 (단위 자체가 논리적임) |
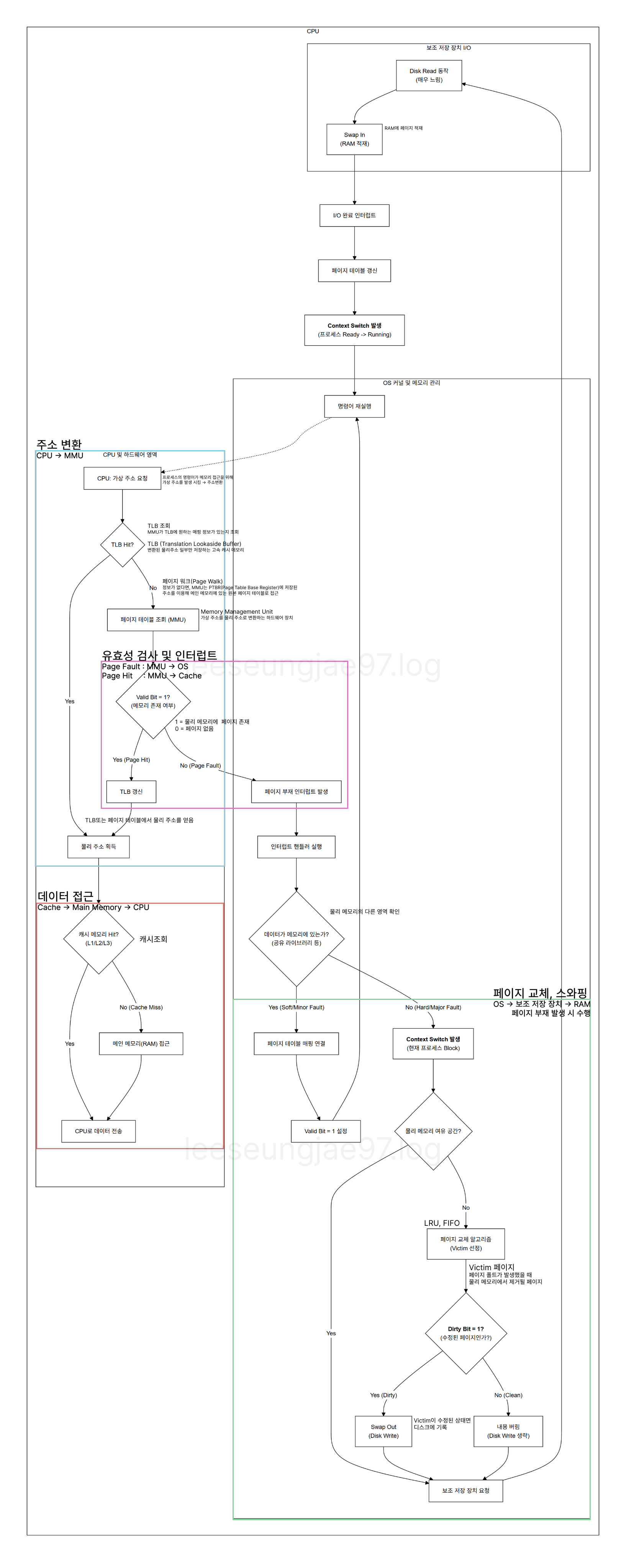
폴트 인터럽트
- 인터럽트 : CPU의 작업을 방해하는 신호
- 동기 인터럽트(except) : CPU에 의해 발생, 프로그래밍 오류
- 폴트 : 예외를 처리한 직후, 예외가 발생한 명령어부터
- 소프트 : 디스크 I/O 없이 처리가능
- 하드 : 디스크 I/O 있어야 처리가능
- 트랩 : 예외를 처리한 직후, 예외가 발생한 명령어의 다음 명령어부터
- 중단 : 프로그램을 강제로 중단
- 소프트웨어 인터럽트 : 프로그램에서 시스템 콜에 의해 생기는 인터럽트
- 폴트 : 예외를 처리한 직후, 예외가 발생한 명령어부터
- 비동기 인터럽트(하드웨어 인터럽트) : 입출력장치에 의해 발생(프린터, 키보드, 마우스)
- 동기 인터럽트(except) : CPU에 의해 발생, 프로그래밍 오류
폴트 인터럽트는 해결하고 실행되어야하는 동기 인터럽트
- 폴트 처리 과정
- CPU가 기존 작업 내역 백업
- 메모리로 원하는 페이지를 가져와 유효비트를 1로 변경
- 폴트를 처리 후 CPU가 해당 페이지에 접근할 수 있게 됨
페이지 폴트
폴트의 일종.
페이지 하드 폴트 일 때 : CPU가 접근하려는 페이지가 물리 메모리에 존재하지 않고
디스크에 있는 경우.
페이지 소프트 폴트 일 때 : CPU가 접근하려는 페이지가 현재 페이지 테이블에는 없지만,
물리 메모리에 존재하는 경우
페이지 폴트는 평시에도 계속 발생함.
프로세스가 데이터를 물리 메모리에서 가져오는 과정
페이징 기준으로 작성
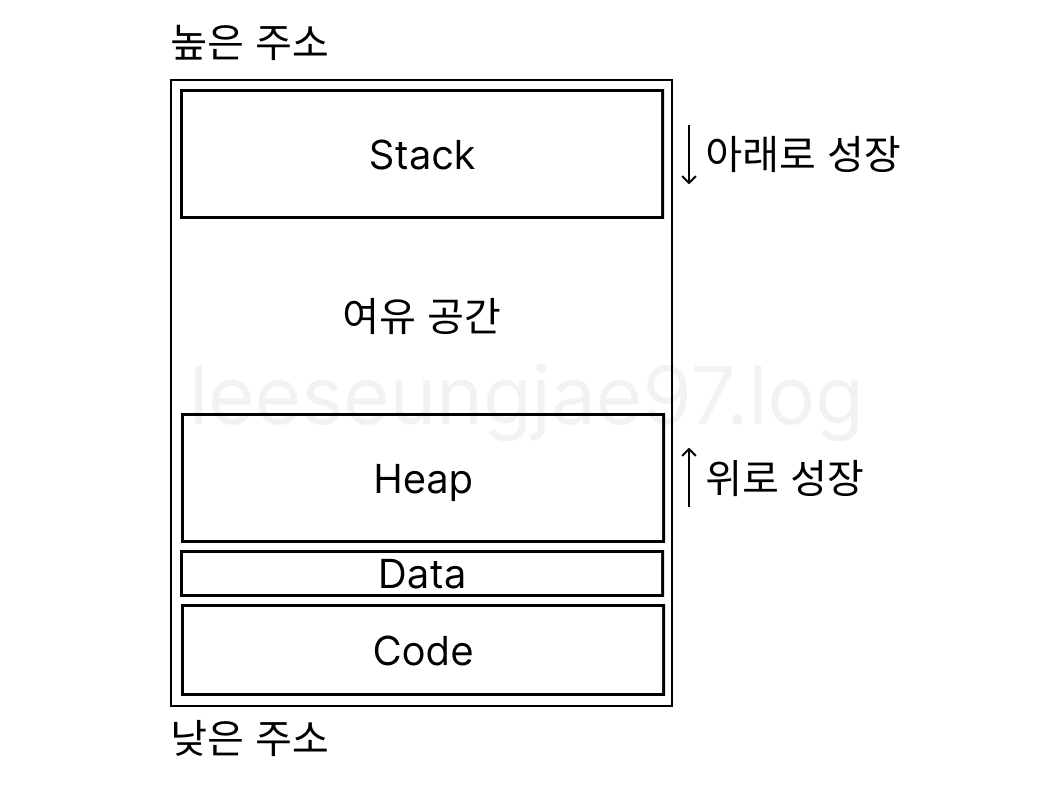
프로세스 메모리 구조
운영체제가 프로세스를 실행하기 위해 할당하는 가상 메모리 공간을 역할과 데이터의 성격에 따라 논리적으로 구분한 구조
| 영역 | 저장 데이터 | 생성 시기 | 소멸 시기 | 관리 주체 | 속도 | 크기 |
|---|---|---|---|---|---|---|
| Code | 기계어 코드 (함수 등) | 컴파일 타임 | 프로그램 종료 | OS | 빠름 | 작성한 코드와 포함된 라이브러리에 비례 |
| Data | 전역/정적 변수 | 프로그램 시작 | 프로그램 종료 | OS | 빠름 | 전역 변수와 static변수의 개수와 크기에 비례 |
| Stack | 지역/매개 변수 | 함수 호출 | 함수 리턴 | 컴파일러(자동) | 매우 빠름 | 기본값 1MB로 설정, RAM 용량만큼 커질 수 있음 |
| Heap | 동적 할당 객체 | 런타임 | 명시적 해제 | 프로그래머 | 느림 | RAM용량 만큼 커질 수 있음 |
Code (Text) 영역
- 프로그래머가 작성한 소스 코드가 컴파일된 기계어가 저장
- 함수코드, 전역 상수, 문자열 상수, 정적 함수
- CPU는 이 영역의 명령어를 하나씩 가져와 실행
- 프로그램 실행 도중 코드가 변경되면 안 되므로 Read-Only임
Data 영역
- 프로그램 시작과 동시에 할당되고, 프로그램이 종료될 때 소멸되는 변수들이 저장됨
- 전역 변수, 정적 변수
- .data: 초기값이 있는 변수 (int a = 10;), 파일 용량을 차지함
- .bss: 초기값이 없는 변수 (int b;) - 파일 내 데이터 크기는 0,
실행하면 RAM에서 0으로 채워짐.
Heap 영역
- 프로그래머가 필요에 따라 런타임에 직접 할당하고 해제됨
- new, malloc 등으로 생성된 객체.
- 메모리 크기 제한이 스택보다 훨씬 큼
- 직접 해제하지 않으면 메모리 누수가 발생
- 스택보다 접근 속도가 상대적으로 느림
Stack 영역
- 함수 호출 시 생성되는 임시 데이터들이 저장되는 곳
- 지역 변수, 매개 변수, 리턴 주소.
- LIFO (Last In, First Out)
- 함수 호출이 끝나면 자동으로 메모리가 해제
- 접근 속도가 매우 빠르지만, 공간이 작아 스택 오버플로우에 주의
// [2. Data 영역] (.data)
// 프로그램 시작 시 생성, 종료 시 소멸. 초기값 있음.
int g_initialized = 100;
// [2. Data 영역] (.bss)
// 프로그램 시작 시 생성, 종료 시 소멸. 초기값 없음(0으로 초기화).
int g_uninitialized;
void TestFunction(int param) // 'param'은 [4. Stack 영역]
{
// [4. Stack 영역]
// 함수 실행 중에만 존재. 함수 종료 시 자동 소멸.
int localVar = 20;
// [3. Heap 영역]
// 'new'로 할당된 실제 int 값(30)은 Heap에 저장됨.
// 단, 그 주소를 가리키는 포인터 변수 'ptr' 자체는 Stack에 존재함.
int* ptr = new int(30);
cout << "Code : " << (void*)TestFunction << '\n'; // 함수의 주소
cout << "Data : " << &g_initialized << '\n';
cout << "Stack: " << &localVar << '\n';
cout << "Heap : " << ptr << '\n';
delete ptr; // Heap 메모리 해제 (필수)
}
int main()
{
TestFunction(10);
return 0; // [1. Code 영역] main 함수의 기계어 명령들
}크기가 거대한 배열은 어디에 두는게 좋을까?
보통 Stack은 1MB로 제한된다. 그래서 Heap에 두고 사용하라고 권장한다.
하지만 Heap과 Stack은 영역을 서로 공유하는데, 내가 선언할 배열의 크기는 명확하다면,
Stack에서 사용하는게 속도적인 면에서 더 빠르고
동적할당으로 만들어진 자원에 대해 신경쓰지 않아도 되니까 편하지 않나?
Stack은 스레드당 할당되는 비용이다. 스레드는 개인적인 Stack영역을 갖는다.
Stack영역을 쪼개서 갖는다는게 아니라 Stack영역 만큼 개인적인 영역을 생성한다.
Stack을 1GB으로 설정하고 스레드를 10개 만들면 10GB을 Stack으로 사용한다.
또, Stack은 위에서 아래로 확장한다. 높은 주소에서 낮은 주소로 무조건 순서대로 쌓여야하므로
메모리 중간에 다른 데이터가 있으면 스택을 확장할 수 없다.
반면 Heap은 연속성으로 쌓이지 않는다. 파편화된 빈 공간을 찾아내어 연결해준다.
메모리 할당
new: 개체 동적 할당- 생성자 호출
new를 오버로딩해 사용할 경우 기존 전역 함수인new(size_t)가 가려진다(name hiding)::new()를 사용해 전역함수임을 명시해야함.
std::bad_alloc을 throw하지 않게 만들 수 있음.nothrownew.obj를 링크해 사용- 클래스별로 다른
operator new를 구현해 사용 new(nothrow)사용
- 타입의 alignment를 보장함.
- operator임,
override가능 operator new → 특정 allocator → 메모리 블록 + alignment + object metadata
malloc: 지정된 바이트 수 만큼 메모리 블록 확보- 타입 안정성 없음, 직접 캐스팅 사용
- 예외처리 없음
malloc → 메모리 블록 할당- 단순한 메모리 할당으로,
vptr을 초기화하지 않는다.
delete: 동적 할당된 메모리 해제- 소멸자 호출
- 메모리 해제
- operator임,
override가능 operator delete → 특정 allocator → 메모리 블록 + alignment + object metadatadelete[]는 각 객체의 소멸자를 순회하며 호출한다.
free: 포인터의 메모리 반환malloc이 관리하던 heap block을 반환free → malloc의 힙 블록에 기록된 크기 & 헤더 참고 → 반환
memset: 특정 메모리 블록을 특정 값으로 초기화하는 데 사용- 빠르게 대량의 메모리 초기화 수행
- 메모리에 직접접근하므로 의도치 않은 결과 초래
- 클래스를 초기화할 때 생성자 호출없이 초기화
- 숫자의 값으로만 초기화가 가능하므로 숫자를 사용하지 않는 타입에 못씀
- 단순한 구조체를 초기화할 때에 사용
잘못된 할당, 해제를 하게되면?
C6280, (VS2026)C26865new→delete,malloc→free를 하지않고 서로 섞어 쓰게되면 컴파일러가 경고를 띄움생성자, 소멸자 호출이 이루어지지 않음
상속 구조에서malloc을 사용하면vptr이 만들어지지 않음.
반대로new를 하고free를 하면 상속관련된 리소스가 해제되지 않음class A { public: int* p; A() { p = new int[10]; } ~A() { delete[] p; } virtual void func() {} }; class B : public A { public: virtual void func() override { A::func(); } };
B* b = (B*)malloc(sizeof(B));
b->func(); // Exception thrown: read access violation.
delete b;
B* b = new B();
b->func();
free(b);
// 40bytes memory leak
---
## placement new
이미 할당된 메모리의 주소에 생성자만 호출하는 문법
```cpp
void* buffer = malloc(sizeof(T));
T* obj = new(buffer) T(10);전달받은 주소를 그대로 반환한다.
void* operator new(std::size_t, void* p) noexcept
{
return p;
}메모리 해제할 때 직접 소멸자 호출하고 free해야함.
obj->~T();
delete obj;
placement delete도 있지만placement new가 메모리 할당에 사용되지 않기 때문에 사용하지 않음.placement delete의 기본 구현에서도 아무것도 하지 않음
inline void __CRTDECL operator delete(void*, void*) noexcept
{
return;
}메모리 누수 방지
메모리 풀링
거대한 메모리 블록을 사전할당 해 두고 placemenet new를 통해 객체 초기화
class MemoryPool
{
private:
char* poolMemory; // 실제 거대 메모리 블록
vector<void*> freeList; // 사용 가능한 메모리 주소들을 보관하는 리스트
size_t objectSize;
size_t poolCapacity;
public:
MemoryPool(size_t size, size_t count) : objectSize(size), poolCapacity(count)
{
// 1. 거대 메모리 할당 (new char[] 사용)
poolMemory = new char[objectSize * count];
// 2. FreeList 초기화 (모든 슬롯을 사용 가능 상태로 등록)
for (size_t i = 0; i < count; ++i)
{
freeList.push_back(poolMemory + (i * objectSize));
}
}
~MemoryPool() { delete[] poolMemory; }
// 메모리 주소만 빌려줌 (할당 X)
void* Allocate()
{
if (freeList.empty())
{
return nullptr; // 풀 꽉 참
}
void* ptr = freeList.back();
freeList.pop_back();
return ptr;
}
// 메모리 주소 반납
void Deallocate(void* ptr) { freeList.push_back(ptr); }
};
int main()
{
MemoryPool monsterPool(sizeof(Monster), 10);
// --- [1] 메모리 포인터 획득 ---
void* ptr1 = monsterPool.Allocate();
if (!ptr1)
{
cout << "메모리 풀이 비어있습니다!" << endl;
return 1;
}
// --- [2] Placement New: 획득한 주소에 객체 생성 ---
// 문법: new (메모리주소) 클래스명(인자);
Monster* m1 = new (ptr1) Monster(100);
cout << "Monster 1 HP: " << m1->hp << endl;
// 다른 객체 생성 시도
void* ptr2 = monsterPool.Allocate();
if (!ptr2)
{
cout << "메모리 풀이 비어있습니다!" << endl;
return 1;
}
Monster* m2 = new (ptr2) Monster(200);
// --- [3] 명시적 소멸자 호출 ---
m1->~Monster();
m2->~Monster();
// --- [4] 메모리 반납 ---
monsterPool.Deallocate(ptr1);
monsterPool.Deallocate(ptr2);
return 0;
}char*배열을 쓰더라도, 각 객체가 시작되는 주소가 alignof(Type)에 맞게 정렬되어 있는지 확인 해야한다.- 코드에서는
sizeof를 사용해 이미 구조체 배수로 패딩함.
- 코드에서는
- 초기 할당에 오버헤드 발생
- 할당해 놓고 사용하지 않으면 내부 단편화 발생
RAII(Resource Acquisition Is Initialization)
자원의 획득을 객체의 생성자에서 수행하고,
자원의 해제를 객체의 소멸자에서 수행하도록 강제함.
객체의 수명을 스코프에 묶는다.
class FileRAII
{
FILE* f;
public:
// 생성자에서 FILE 포인터 초기화, 객체 생성
explicit FileRAII(const char* name)
: f(fopen(name, "r")) {}
// 소멸자에서 FILE 포인터 해제
~FileRAII()
{
if (f) fclose(f);
}
};
void func()
{
FileRAII fr("test.txt");
...
// 알아서 해제됨.
}빅 엔디안, 리틀 엔디안 : 메모리에 바이트를 밀어 넣는 순서
빅 엔디안 : 낮은 번지의 주소에 상위 바이트부터 저장하는 방식(일상적인 숫자 체계와 동일)
리틀 엔디안 : 낮은 번지의 주소에 하위 바이트부터 저장하는 방식(수치 계산에 편리)
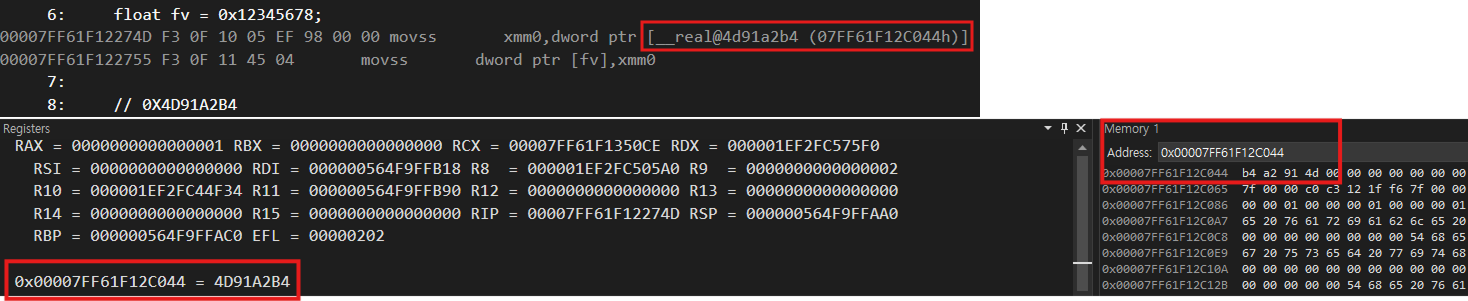
0x12345678이 있을 때
0x12이 가장 큰 자릿수(MSB: Most Significant Byte, 쉽게말해 가장 왼쪽 비트)
0x78이 가장 작은 자릿수(LSB: Least Significant Byte, 가장 오른쪽 비트).
빅 엔디안 : 12 34 56 78
리틀 엔디안 : 78 56 34 12
intel에서는 리틀 엔디안으로 저장하고 있다.
메모리는 CPU의 연산 속도와 저장 장치의 용량 사이의 간극을 메우기 위해 계층화된 구조를 가지며,
가상 메모리와 캐시 지역성을 활용하여 한정된 물리적 자원을 논리적으로 확장하고
데이터 접근 효율을 극대화하는 전략적 저장 공간이다.
문제
20문제
https://gemini.google.com/share/e85c4779901a
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.