동일한 타입의 데이터를 메모리상에 연속적으로 배치하여 관리하는 가장 기본적인 자료구조
int arr[5] = {1,2,3,4,5};arr
[1][2][3][4][5]
^ ^ ^ ^ ^
+0 +4 +8 +12 +16 (int = 4byte 기준)- 캐시 효율성: 데이터가 메모리에 나란히 붙어 있기 때문에, CPU가 데이터를 읽을 때 캐시 라인(64바이트) 단위로 주변 데이터까지 함께 가져와 공간 지역성(Spatial Locality) 을 극대화하여 캐시 히트율을 높인다.
- 랜덤 액세스( $O(1)$ ): 배열의 시작 주소를 알고 있다면, 시작 주소 + (인덱스 × 요소 크기) 을 통해 원하는 위치에 즉시 접근.
arr[2]; *(arr + 2);
컴파일 타임에 크기가 결정되는 정적배열과 런타임에 크기가 결정되는 동적 배열이 있다.
정적배열은 전역인 경우 Data영역에 함수 내부인 경우에 Stack 영역에 할당된다.
동적배열은 Heap 영역에 할당되고 할당과 해제를 직접 해주어야한다.
다차원 배열
배열안에 배열이 있는 구조, 이 중첩을 차원이라고 표현한다.
[] == 차원(dimension)[] : 1차원 배열[][] : 2차원 배열[][][] : 3차원 배열
...
포인터 변환
배열 이름은 배열의 시작주소를 가지고있다.
시작주소를 가지고 있기 때문에 포인터 변환이 가능하다.
int arr[5] = {1,2,3,4,5};
void* vp = arr;
int* ip = arr;
// void*의 경우, 포인터 연산을 하기 위해 타입이 필요함
cout << *(static_cast<int*>(vp) + 1) << '\n';
cout << *(ip + 1) << '\n';함수 인자에서 배열
배열은 값 타입이 아닌 메모리 블록 + 시작 주소로 취급되는 타입이기 때문에
함수 인자에서는 항상 포인터로 조정된다.
C언어 부터 배열은 주소만 넘기도록 강제했다.
void foo(int arr[5]) → void foo(int* arr)int arr[5]
void foo(int arr[5]) ⭕
void foo(int* arr) ⭕
void foo(int& arr) ❌
void foo(int (&arr)[5]) ⭕
template<size_t N> void foo(int (&arr)[N]) ⭕
template<size_t N> void foo(int arr[N]) ❌2차원 이상의 배열
int arr[5][5]
void foo(int arr[5][5]) ⭕
void foo(int (*arr)[5]) ⭕
void foo(int** arr) ❌
void foo(int (&arr)[5][5]) ⭕
template<size_t N, size_t M> void foo(int (&arr)[N][M]) ⭕
template<size_t N, size_t M> void foo(int arr[N][M]) ❌int* arr은 배열의 시작주소를 가리키는 거였고.int** arr은 배열의 시작주소가 가리키는걸 가리키는 것이다.
int** arr의 + 1은 8bytes,int (*arr)[5]의 + 1은 20bytes.int arr[5][5]의 + 1은 4bytes.
int arr[5][5] → [ a[0][0] a[0][1] ... a[0][4] ]
[ a[1][0] a[1][1] ... a[1][4] ]
...
int** arr → [ptr][ptr][ptr][ptr][ptr]
↓ ↓ ↓
row0 row1 row2 ...int* arr[5]타입은 2차원 배열을 받을 수 있다.
std::vector
연속된 메모리를 사용하는 가변 크기 배열
내부 구조는 3개의 포인터로 구성된다.
T* begin; // 시작 주소
T* end; // 실제 사용 끝 (size)
T* capacity; // 할당 끝 (capacity)[ element ][ element ][ element ][ unused ][ unused ]
^begin ^end ^capacity요소 추가
push_back()을 통해 배열 뒤에 요소 추가emplace_back()도 똑같이 요소를 추가한다.emplace_back()은 perfect forwarding을 사용한다.
| 전달하는 것 | push_back |
emplace_back |
|---|---|---|
lvalue (x) |
복사 생성 | 복사 생성 |
xvalue (std::move(x)) |
이동 생성 | 이동 생성 |
prvalue (T(...)) |
보통 생성 + 이동 | 직접 생성 |
capacity
capacity는 보통 2배씩 증가한다.
v.push_back(1); // capacity 1
v.push_back(2); // capacity 2
v.push_back(3); // capacity 4 (재할당)reserve()를 통해 미리 capacity를 확보하게 할 수 있음.resize()를 통해 size를 변경한다. 변경된 size만큼 새 요소를 기본 생성한다.
재할당
vector는 iterator를 통해 순회하거나, v.data()를 통해 포인터를 반환한다.
vector<int>::iterator iter = nums.begin();
int* p = nums.data();요소를 추가하면서 재할당(capacity 변경)이 일어나면 iterator와 포인터는 무효화된다.
capacity가 재할당 되는 과정은 기존 구조에 메모리를 추가하는게 아닌
기존 메모리를 해제하고 더 큰 메모리를 할당하는 과정을 거치기 때문이다.
그렇게 되면 iterator와 포인터는 해제된 공간을 가리키는 댕글링 포인터가 된다.
iterator->old, p->old
[1][2][3][4] (capacity = 4)
↓
push_back(5), emplace_back(5)
↓
old: [1][2][3][4]
new: [ ][ ][ ][ ][ ][ ][ ][ ]
↓
old: (free)
new: [1][2][3][4][5][ ][ ][ ]
iterator->old(free), p->old(free)reserve()를 통해 미리 공간을 확보해 재할당이 일어나지 않게하면
요소를 추가해도 댕글링 포인터가 되지 않는다.
vector<int> nums;
nums.reserve(100);
nums.push_back(10);
nums.push_back(20);
int* p = nums.data();
nums.push_back(30);
for (int i = 0; i < nums.size(); ++i)
cout << p[i] << ' ';std::deque
double-ended queue로 앞/뒤로 삽입, 삭제가 가능하다.
배열들과 배열을 저장하는 배열로 이루어져있다.
내부적으로 슬라이딩 윈도우 알고리즘을 이용한다.
이중 배열 구조인 이유
push_back(1);
push_back(2);
push_front(3);
push_front(4);
push_front(5);단일 배열로 했을 때.
[ _ _ _ | 1 2 | _ _ _ ]
^start ^end
[ 5 4 3 | 1 2 | _ _ _ ]
^ start가 0에 도달
[ _ _ _ _ _ _ _ _ ] 기존 컨테이너 free
[ _ _ _ _ 5 4 3 | 1 2 | _ _ _ _ _ _ _ ]이중 배열 구조인 경우
map (포인터 배열)
[B2][B1][ ]
B1: [ 1 2 _ ]
B2: [ 5 4 3 ]
[ _ _ _ ] 기존 컨테이너 free
[][B3][B2][B1][][][]
B1: [ 1 2 _ ]
B2: [ 5 4 3 ]
B3: [ _ _ _ ]이중 배열이면 배열을 담는 포인터 배열만 관리하면 된다.
해제와 할당하는 메모리 크기가 훨씬 작아진다.
2차원 배열 구조이기 때문에 일반 배열보다 캐시 지역성이 떨어지고
순회가 무겁다($O(N^2)$)
std::queue
FIFO(First-In, First-Out) 정책을 강제하는 컨테이너 어댑터
기본 컨테이너는 deque이다.
template<
class T,
class Container = std::deque<T>
>
class queue;FIFO를 강제하기 위해 순회를 막아, iterator가 없다.front()를 통해 앞 요소 가져오고 pop()을 통해 앞 요소 삭제
queue
[3][2][1]
^front
push(4)
[4][3][2][1]
^front
pop()
[4][3][2]
^frontstd::stack
LIFO(Last-In, First-Out)정책을 강제하는 컨테이너 어댑터
template<
class T,
class Container = std::deque<T>
>
class stack;queue와 마찬가지로 기본 컨테이너는 deque이고FILO강제를 위해 iterator가 없다.top()을 통해 뒷 요소 가져오고 pop()을 통해 뒷 요소 삭제
stack
[3][2][1]
^top
push(4)
[4][3][2][1]
^top
pop()
[3][2][1]
^top| 항목 | std::vector |
std::deque |
std::queue |
std::stack |
|---|---|---|---|---|
| 구조 | 단일 연속 배열 | 블록 + 포인터 배열 | deque 기반 어댑터 | deque/vector 기반 어댑터 |
| 접근 | O(1) (빠름) | O(1) (느림) | front/back만 | top만 |
| 중간 삽입 | O(n) | O(n) | 불가 | 불가 |
| iterator | ⭕ | ⭕ | ❌ | ❌ |
| iterator 안정성 | 낮음 (realloc 시 무효) | 중간 | 내부 컨테이너 의존 | 내부 컨테이너 의존 |
| 재할당 비용 | 큼 (전체 이동) | 작음 (포인터만 이동) | 내부 컨테이너 의존 | 내부 컨테이너 의존 |
| 컨테이너 | 설명 |
|---|---|
| vector | 빠른 배열 (cache 최적화) |
| deque | 양쪽 확장 가능한 배열 |
| queue | FIFO 인터페이스 제한기 |
| stack | LIFO 인터페이스 제한기 |
std::list
이중 연결 리스트(doubly linked list) 기반 컨테이너
메모리에 연속적으로 존재하지 않는 노드 기반 구조
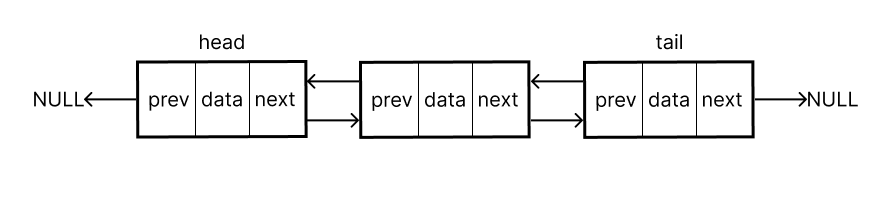
struct Node
{
T data;
Node* prev;
Node* next;
};각 노드는 포인터로 연결된다.
노드 기반이기 때문에 데이터 추가/삭제에 재할당이 발생하지 않는다.
그러므로 iterator 무효화가 발생하지 않는다.
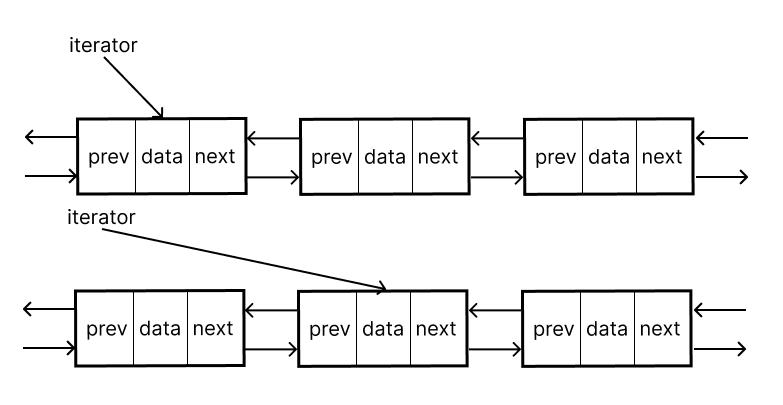
포인터 기반이기 때문에 인덱싱을 할 수 없다.
list1.splice(list1_iterator, list2)로 포인터를 재연결 할 수 있음.list2의 노드를 list1에 재연결, list2는 연결을 끊는다.
삽입
$O(1)$로 동작
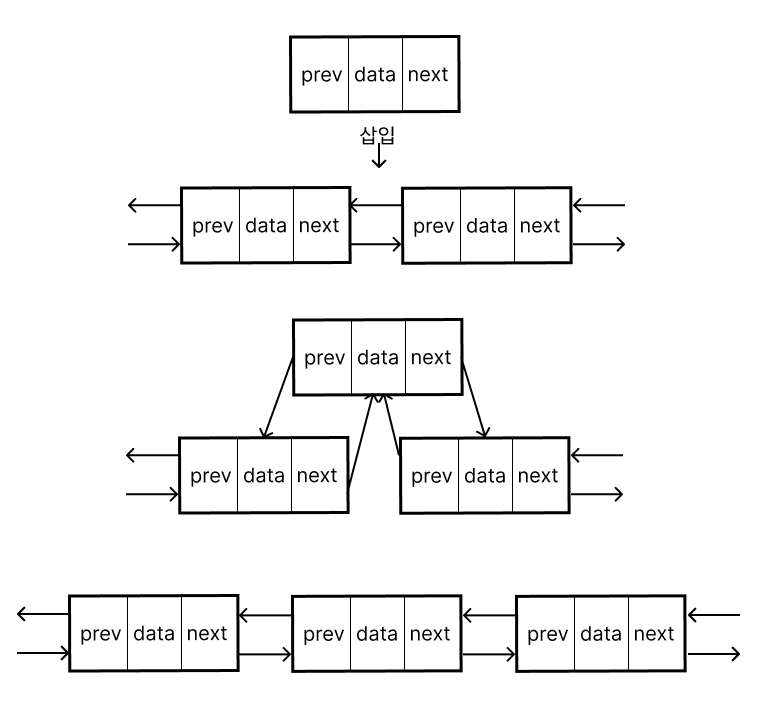
찾기
$O(N)$으로 동작
삭제
$O(1)$로 동작
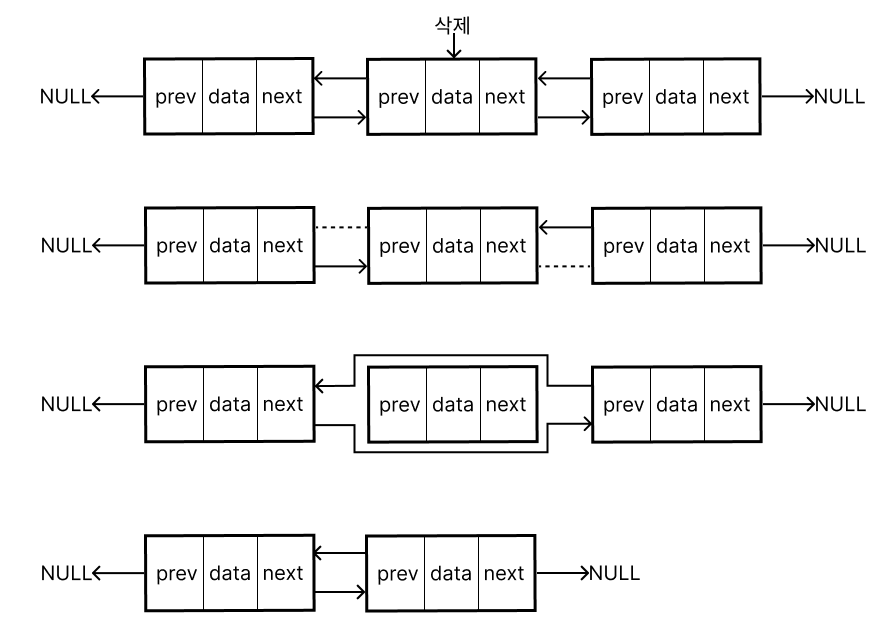
삭제할 노드의 포인터의 연결을 끊어주고 이전노드와 다음노드를 연결해준다.
Singly Linked List
node -> node -> nodenext만 있음, 메모리 적음, 역방향 이동 불가
Doubly Linked List
prev <-> node <-> next양방향 이동, 삭제 O(1), 메모리 증가
Circular List
tail -> head 연결끝이 없음, 반복 구조에 유리
| 항목 | 배열 (Array / std::vector) |
연결 리스트 (std::list) |
|---|---|---|
| 메모리 구조 | 연속적 (contiguous) | 비연속 (node chain) |
| 접근 방식 | 인덱스 기반 arr[i] |
iterator / 포인터 |
| 임의 접근 | ✅ O(1) | ❌ O(n) |
| 순차 접근 | 매우 빠름 (cache-friendly) | 느림 (cache miss) |
| 중간 삽입 | ❌ O(n) (밀기 필요) | ✅ O(1) (포인터 변경) |
| 중간 삭제 | ❌ O(n) | ✅ O(1) |
| 맨 앞 삽입 | ❌ O(n) | ✅ O(1) |
| 맨 뒤 삽입 | amortized O(1) | O(1) |
| 메모리 효율 | 좋음 | 나쁨 (prev/next 포인터) |
| cache locality | 매우 좋음 | 매우 나쁨 |
| iterator 안정성 | ❌ (재할당 시 무효화) | ✅ (거의 유지됨) |
| 정렬 | std::sort (빠름) |
자체 sort (merge sort) |
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.