Hash Map(STL unordered_map)
Hash Table + Hash function + Bucket Array + Chaining
Hash Value는 Hash Function에 의해 만들어진 고정된 길이의 값을 말한다.
서로 다른 Key가 같은 Hash Value을 가질 수 있으며 이를 충돌(collision, crash)이라 한다.
Hash Function
임의의 길이를 지닌 데이터를 고정된 길이의 데이터로 변환하는
단방향 함수를 뜻한다.
단방향이므로 특정 입력 데이터를 고정된 길이의 Hash Value 변환은 해도Hash Value로 어떤 데이터가 입력되었는지 도출하기는 어려움
Hash Algorithm으로 SHA-1, SHA-256, SHA-512, MD5등이 있다.
Ada Lovelace를 MD5로 암호화 하면 f27c21cf2280e80ed60b8ab492a4030b가 나온다
MD5 암호화 사이트, MD5에 대한 설명과 복호화에 대해서도 설명한다.
https://md5decrypt.net/en/
복호화가 어렵다는 특징으로 단방향 암호를 만들거나 데이터의 무결성을 검증하기 위해 사용된다.
하지만 unordered_map의 Hash는 역추적 가능하고 보안 목적과는 관련이 없다.
빠른 계산과 균등 분포를 위해 사용한다.
Hash + Table
Table은 Key와 Value의 대응으로 이루어진 표와 같은 형태 자료구조를 뜻한다.Key는 Table에 대한 입력, Value는 Key통해 얻고자 하는 데이터이다.
이 과정은 평균적으로 O(1) 시간 복잡도를 가지며, 충돌이 많을 경우 최악 O(N)이 될 수 있다.
Hash Table은 Key에 Hash function를 적용하여 얻은 인덱스를 통해 값을 저장하고 탐색하는 자료구조이다.
Hash Table은 Key를 통해 얻고자 하는 데이터는 Bucket에 저장되어 있다.Bucket은 여러개가 존재하고, 여러 Bucket들은 배열을 형성한다.
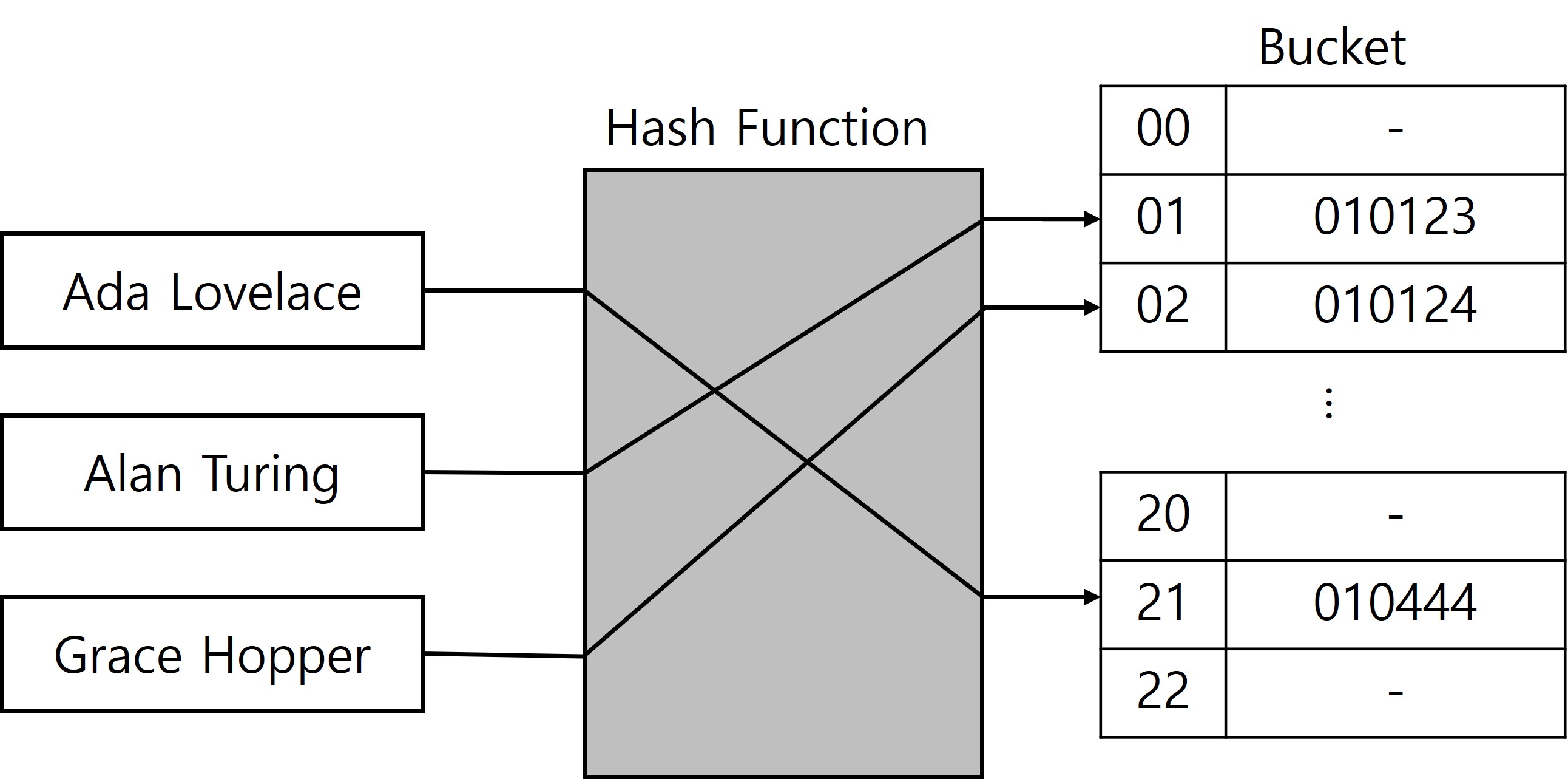
Hash Collision
Hash function으로 나온 Key값이 겹칠 때 발생한다.

이 자료로 진행함 https://github.com/kangtegong/cs/tree/main/ds/hash
다른 자료임에도 같은 Hash Value가 나왔다.
해결방법으로
- Chaining →
충돌이 발생한 데이터를LinkedList로 추가한다.
장점 : 구현이 단순하고 삭제에 O(1)이 걸린다.
단점 : 캐시 지역성이 나쁨, 메모리 단편화 발생 확률 ↑ - Open addressing →
충돌 시 다른 빈 슬롯을 탐색하여 저장, 탐색하는 과정을 probe(조사)라고함
장점 : 캐시 지역성이 좋고, 메모리 효율이 높음
단점 : 삭제가 복잡하고 클러스터링 발생,ReHashing비용이 있음2-1. Linear probing →
충돌이 발생했을 때 충돌이 발생한 인덱스의 다음 인덱스부터
사용가능한 슬롯인지 찾는 방법. - 클러스터링(Clustering)은 여러 데이터가 몰려 저장되는 문제점을 말한다.
- Double hashing →
충돌이 발생한 인덱스의 이동 간격을Hash로 결정한다.
장점 : 클러스터링이 최소화됨.
단점 :Hash를 2번 계산해야함. 구현복잡
| 항목 | Chaining | Open Addressing | Linear Probing | Double Hashing |
|---|---|---|---|---|
| 구조 | bucket list | 배열 | 배열 | 배열 |
| 충돌 해결 | 리스트 | probe | +1 | hash2 |
| 메모리 | 큼 | 작음 | 작음 | 작음 |
| 캐시 | 나쁨 | 좋음 | 매우 좋음 | 좋음 |
| 삭제 | 쉬움 | 어려움 | 어려움 | 어려움 |
| 클러스터링 | 없음 | 있음 | 심각 | 거의 없음 |
| 구현 난이도 | 쉬움 | 중 | 매우 쉬움 | 어려움 |
| 성능 안정성 | 높음 | 중 | 낮음 | 높음 |
HashSet
Set은 중복을 허용하지 않는 원소들의 모임을 Key로 사용하는 자료구조.
C++ STL기준, RBTree로 구현되어 있어서,RBTree의 특성(정렬, 탐색/삽입O(log N))을 가지고 있다.
HashSet은 Key만 저장한다는 점을 제외하면 HashMap과 동일한 구조를 가지며,
개념적으로 HashSet = HashMap<Key, void>로 볼 수 있다.
Rehashing
Hash Table의 Bucket 개수를 늘리거나 줄이면서, 기존에 저장된 모든 원소를 새로운 Bucket Array에 다시 배치하는 과정을 말한다.
Bucket의 크기를 바꾸면 배열 크기만 바뀌는게 아니라
모든 원소를 다시 Hashing해야 한다.Hash Table은 원소 인덱스를 Hash(key) % Bucket count로 지정하기 때문에Bucket count가 달라지면 원소 저장위치가 원하는 곳에 있지 않게 된다.
Bucket_count = 8;
기존_index = 42 % 8 = 2
Bucket_count = 16;
바뀐_index = 42 % 16 = 10load factor는 원소 개수를 Bucket으로 나눈 값으로Bucket하나 당 Chaining된 평균 원소 수를 의미한다.
load_factor = size / bucket_count;load factor가 커질 수록 Bucket chain이 길어지고 탐색 성능이 떨어진다.Hash container들은 load factor가 특정 임계값을 넘으면 Bucket수를 늘리고
원소를 ReHashing해 새로운 위치로 옮겨야 한다.
FlatMap(C++23)
Key-Value쌍이 담긴 배열이 항상 Key기준으로 정렬되어 있다.
이진 탐색으로 이 배열을 탐색한다. 탐색 복잡도는 O(log N)이지만
배열구조를 사용하고 있기 때문에 순회가 캐시 친화적이다.
삽입/삭제후 에 뒤 원소들을 이동 시켜야하기 때문에 O(N)비용이 발생한다.
기존 C++ STL Map과 인터페이스는 동일하다.
참고 문헌
이것이 컴퓨터 과학이다 with CS 기술 면접
문제
객관식 10문제
https://gemini.google.com/share/033f71d0f77d
정렬이 필요하지 않은 상황인데도
게임 코드에서 unordered_map보다 map을 선택하는 것이 더 적절한 경우는 언제인가요?해시 충돌(Hash Collision)이 무엇이고, 어떻게 해결할 수 있는지 설명해보세요.
배열 대신 연결 리스트를 사용하는 것이 성능에 유리한 경우가 있다면 설명해보세요.
Hash Table의 장단점을 설명해보세요.
게임 내 수만 개의 총알 객체를 관리해야 합니다. 이때
unordered_map을 사용하는 것과vector를 사용하는 것 중 어느 것이 CPU 캐시 히트율 측면에서 유리하며, 그 이유를 메모리 레이아웃 관점에서 설명해 주세요.
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.