Class
멤버 변수와 멤버 함수의 목록을 정의한 설계도이다.
빌드 과정 중에는 데이터 영역이나
코드 영역의 크기를 계산하는 기준이 된다.
Class에 정의된 변수들이 실제로 메모리(Stack 또는 Heap)에 할당된 상태를 객체(Instance)라고한다.
메모리 영역에 따라 Instance 생성이 나뉜다.
지역Instance (Stack)
Player p1;빠르고 함수가 끝나면 자동으로 소멸된다.
동적 Instance 할당 (Heap)
Player* p2 = new Player(); // Heap에 할당p2는 Stack영역에 있지만Player Instance 데이터는 Heap에 저장된다.
멤버
클래스 내부에 있는 변수를 멤버 변수, 내부에 있는 함수를 멤버 함수라고 한다.Instance가 생성되면 메모리에는 멤버 변수들만 쌓인다.
멤버 함수는 객체 내부에 포함되지 않고, 코드 영역에 딱 하나만 존재하고, 모든 Instance가 공유한다.
함수 호출 시 암시적으로 전달되는 this 포인터가 Instance의 것이 온다.
멤버 함수
일반 멤버 함수는 컴파일 타임에 코드 영역에 딱 하나만 생성된다. 모든 Instance가 함수를 공유한다.
class A
{
public:
void func() { cout << "compile time A func()"; }
}
A* a = nullptr;
a->func();nullptr인데 터지지 않을까?a->func()는 컴파일 타임에 내부적으로 A::func(a)와 같은 형태로 변환된다.
a->func();
// 컴파일러가 변환한 실제 호출 (의사 코드)
A::func(nullptr); // 여기서 a는 nullptr여기서는 this를 통한 별다른 동작을 하지 않으므로 실행이 된다.
생성자
Class로 부터 Instance가 생성될 때 가장 먼저 호출되는 특수 함수.Instance는 내부의 변수들을 초기화하고, 필요한 자원을 할당한다.Class 이름과 동일하고 반환타입이 없다.
생성자는 멤버를 초기화 할 때 초기화 리스트(member initializer list)를 작성할 수 있다.
A() : b(0), c(0.0f) {}초기화 리스트는 Class가 메모리에 올라가 Instance가 되는 순간 값이 들어온다.
내부에서 대입은 Instance가 만들어지고 몸체 안에서 대입이 일어난다.
A()
{
b = 0;
c = 0.0f;
}Class를 Instance할 때 초기값을 제공하지 않으면 기본 생성자가 호출된다.Overload를 이용해 매개 변수를 다르게해 매개 변수가 있는 생성자도 만들고 호출할 수 있다.
Class에 생성자가 명시되어 있지 않으면 컴파일러가 암시적으로 기본 생성자를 생성한다.
컴파일러가 암시적으로 기본 생성자를 호출하는걸 막으려면 delete하면된다.
A() = delete;기본 생성자가 없는 경우 대괄호 구문만으로는 해당 클래스의 객체 배열을 생성할 수 없다.
class Box
{
...
public:
Box(int x, int y) : m_x(x), m_y(y) {}
}
Box Boxes[3]; // 컴파일 에러
Box Boxes[3]{{1,2}, {2,3}, {3,4} };복사 생성자(Copy Constructor)
기존 Instance를 사용해 새로운 Instance를 초기화 할 때 호출되는 생성자
class MyClass
{
MyClass(const MyClass& other)
{
// other의 데이터를 현재 객체로 복사하는 로직
}
};복사 생성자의 매개변수는 반드시 참조자여야한다.
MyClass(MyClass other) // 참조자가 아니면 여기서
// 또 복사 생성자가 호출된다. 무한 재귀Instance내부에 힙 영역 주소를 담는 변수가 하나라도 있다면 컴파일러가 만들어주는
기본 복사 생성자에 의존하면 안된다. 직접 Deep Copy가 되게 만들어줘야한다.
A(const A& other)
{
this->a = new int[10];
for(int i = 0 ; i < 10; ++i)
{
this->a[i] = other.a[i];
}
}복사 생성자는 다음과 같은 상황에서 컴파일러가 호출한다.
Instance로 다른Instance를 명시적으로 초기화 할 때MyClass c1; // 기본 생성자 호출 MyClass p2 = p1; // 복사 생성자 호출 MyClass p3(p2); // 복사 생성자 호출Instance를 함수에 값으로 전달할 때 Pass By Valuevoid Func(Player p) {} // 복사 생성자 호출 Func(p1);이 과정에서 복사 생성자가 호출되면 성능 오버헤드가 발생할 수 있어서 참조자를 써서 생략한다.
void Func(Player& p) {} Func(p1);함수에서
Instance를 값으로 반환할 때MyClass Func() { MyClass temp(10); return temp; }최신 컴파일러는 최적화를 통해 생략하기도 함(copy elision, RVO).
복사 대입 연산자(Copy assignment operator) 와 비슷하다.
Player p2 = p1; // (1) 복사 생성자: 새로운 p2가 태어나는 중
p2 = p3; // (2) 복사 대입 연산자: 이미 태어난 p2의 내용물을 바꾸는 중이미 존재하는 Instance이므로 기존에 가진 메모리를 먼저 delete하는 등의 추가 처리 필요.
컨테이너에 값을 삽입할 때 빈 객체를 만든 뒤 채우는 것이 아니라
기존 객체와 동일한 의미를 갖는 객체를 생성하는 행위이기 때문에 기본 생성자가 아닌 복사 생성자를 사용한다.
복사 대입 연산자(Copy assignment operator)
이미 있는 Instance의 데이터를 다른 Instance의 데이터로 교체하는 것.
MyClass& operator=(const MyClass& other)
{
if (this == &other) return *this
delete data;
data = new int(*other.data);
return *this;
}Instance내부에 Heap영역의 주소를 가진 변수가 있을 때, 단순히 값을 복사하면 안된다.
- 자기 대입 검사를 해야한다. 내부 데이터를 지우고 대입하는데 자기 자신이면
자기 자신을 지우고 자기 자신의 데이터를 복사해 올 수 없다. - 기존 자원 해제
데이터가 바뀌는 피Instance의 데이터를 해제 해준다. - Deep Copy(깊은 복사) 진행. Heap 할당, 내용 복사
MyClass mc1(10); // 생성자 호출
MyClass mc2(10);
mc1 = mc2; // 복사 대입 연산자 호출
MyClass mc1 = mc2; // 복사 생성자 호출| 구분 | 복사 생성자 | 복사 대입 연산자 |
|---|---|---|
| Instance 상태 | 이제 막 생성되는 중 | 이미 생성되어 있음 |
| 메모리 해제 | 필요 없음 (빈 땅임) | 필요함 (기존 땅을 치워야 함) |
| 반환값 | 없음 | Myclass& (자기 자신을 참조로 반환) |
T a, T* p1 일 때 |
호출 연산 | 설명 |
|---|---|---|
T b = a; |
복사 생성자 | 선언과 동시에 초기화 |
T b(a); |
복사 생성자 | 직접 생성자 호출 방식 |
T* p2 = nullptr; p2 = p1; |
얇은 복사 | 주소값만 복사 |
T& r = b; r = a; |
대입 연산자 | b = a와 같음 |
T b = *p1; |
복사 생성자 | p1이 가리키는 재료로 Instance 생성 |
new T(*p1); |
복사 생성자 | Instance만들고 *p1 전달 |
Copy elision(복사 생략)
컴파일러가 최적화 과정에서 임시 Instance의 생성을
생략하고 복사/이동 생성자의 호출을 건너뛰는 행위
함수 내부에서 만든 Instance는 외부로 전달할 때, 원래라면 새로운 변수에 값을 복사해야 하지만
컴파일러가 처음부터 결과물이 담길 자리에 직접 Instance를 생성해버린다.
RVO(Return Value Optimization)
이름없는 임시 인스턴스를 반환할 때 복사 생략
이름 없는 임시 객체를 반환할 때 복사/이동이 생략되는 최적화이다.
C++17부터는 일부 prvalue 문맥에서 임시 객체를 따로 만들지 않고
결과 객체가 직접 생성되도록 규칙이 바뀌었다.
MyClass Func()
{
return MyClass(100); // 이름 없는 임시 인스턴스 반환
}
MyClass mc = Func();RVO 적용 전
- 함수 내부에서 임시
Instance생성 : 생성자 호출 - 반환 시 복사 생성자로
mc에 복사 : 복사 생성자 호출 - 함수 내부 임시
Instance소멸 : 소멸자 호출
RVO 적용 후
- 컴파일러가
Func에mc의 메모리 주소를 미리 알려준다. Func는 그 주소에 100을 채워 넣음. : 생성자 호출
NRVO(Named Return Value Optimization)
이름이 있는 지역 Instance를 반환할 때 복사 생략
MyClass Func()
{
MyClass temp(100);
temp.classFunc(10);
return temp;
}
MyClass mc = Func();함수 내부 지역 변수인 temp를 별도의 메모리에 만들지 않고,mc와 동일한 공간으로 간주하고 작업함.
함수 내부에서 if문 등 반환되는 Instance가 달라지는 등,
경로가 복잡하면 컴파일러가 NRVO를 포기할 수도 있음.
이동 생성자(Move constructor)
함수에서 큰 데이터를 가진 Instance를 반환하거나, 곧 사라질 임시 Instance의
데이터를 옮겨야 할 때 사용된다.
복사 생성자를 쓰면 데이터를 일일이 복사해야한다.
원본 Instance가 곧 사라질 거면, Heap 주소 값만 새 Instance에 넘겨주고 원본은 nullptr로 만듬
MyClass(MyClass&& other) noexcept
{
data = other.data;
other.data = nullptr;
}other.data를 nullptr로 바꿔줘야 other이 소멸될 때 Heap 메모리가 날아가지 않는다.
이동 생성자는 새로 생기는 Instance에 기존 Instance를 넣을 때 호출된다.
rvalue 참조로 받는 이유는 안전을 위해 곧 사라질 Instance만 받기 위해서다.
이동 대입 연산자(Move assignment operator)
이미 있는 Instance가 다른 Instance의 자원을 뺏어오는 연산자.
MyClass& operator=(MyClass&& other) noexcept
{
if(&other == this)
return *this;
if(nullptr != data)
delete data;
data = other.data;
other.data = nullptr;
return *this;
}이동 생성자와 마찬가지로 other.data를 nullptr로 바꿔줘야 other이 소멸될 때 Heap 메모리가 날아가지 않는다.
해제하고 nullptr로 바꿔주기 때문에 꼭 자기 자신인지 확인해야한다.
move를 이용할 때 이동 생성자와 이동 대입 연산자가 꼭 필요하다.
소멸자
객체가 메모리에서 사라지기 전에 마지막으로 호출되는 특수 함수
객체가 사용하던 자원을 해제한다.Class 이름 앞에~가 붙고, 매개변수와 반환 타입이 없다.
소멸자에 private를 붙이면 해당 객체를 스택에 생성하지 못한다.
오직 new를 통해 Heap에만 생성하고 정해진 관리 함수를 통해서만 죽게 만들 수 있다.
class A {
private:
~A() {}
public:
void Destroy() { delete this; }
};
// A stack; // 에러: 스택 생성 불가 (소멸자 호출 불가)
A* heap = new A();
// delete heap; // 에러: 외부에서 private 소멸자에 접근 불가
heap->Destroy(); // OK: 공인된 절차를 통한 파괴Struct
C++에서 Class와 Struct는 기술적으로 거의 동일하다. 둘의 구분은
철학적인 용도와 기본 접근 제어자에서 차이난다.
Struct는 기본 접근 제어자가 public, Class는 private이다.
기본 상속 지정자도 Struct은 public, Class는 private이다.
Struct는 데이터를 하나로 묶어서 전달하는 것이 목적일때 사용한다.
캡슐화 보다는 편의성에 집중한다.
Class는 데이터와 그 데이터를 다루는 로직을 감추는 Instance를 만들 때 사용한다.
외부에서 마음대로 변수를 수정하지 못하게 막고, 함수를 통해서만 소통하도록 강제한다.
객체 지향 프로그래밍(OOP)
모든 데이터와 로직을 독립적인 사물로 본다는 프로그래밍.
객체하면 Object와 연관지어지는데OOP에서 Object는 데이터 덩어리 자체를 뜻한다.
근데Object라면서 OOP의 특성중 다형성, 상속은 아예 Class에만 해당되는 이야기다.OOP가 Class를 생각하고 만든게 아니였는데 Class기반에서 개념이 사용되다 보니Class 내용이 추가 되었다. OOP의 원론의 주체는 '객체'가 아닌 메시징이다.
C++은 Class라는 틀을 통해서만 상속과 다형성을 구현하도록 제약한 것이다.
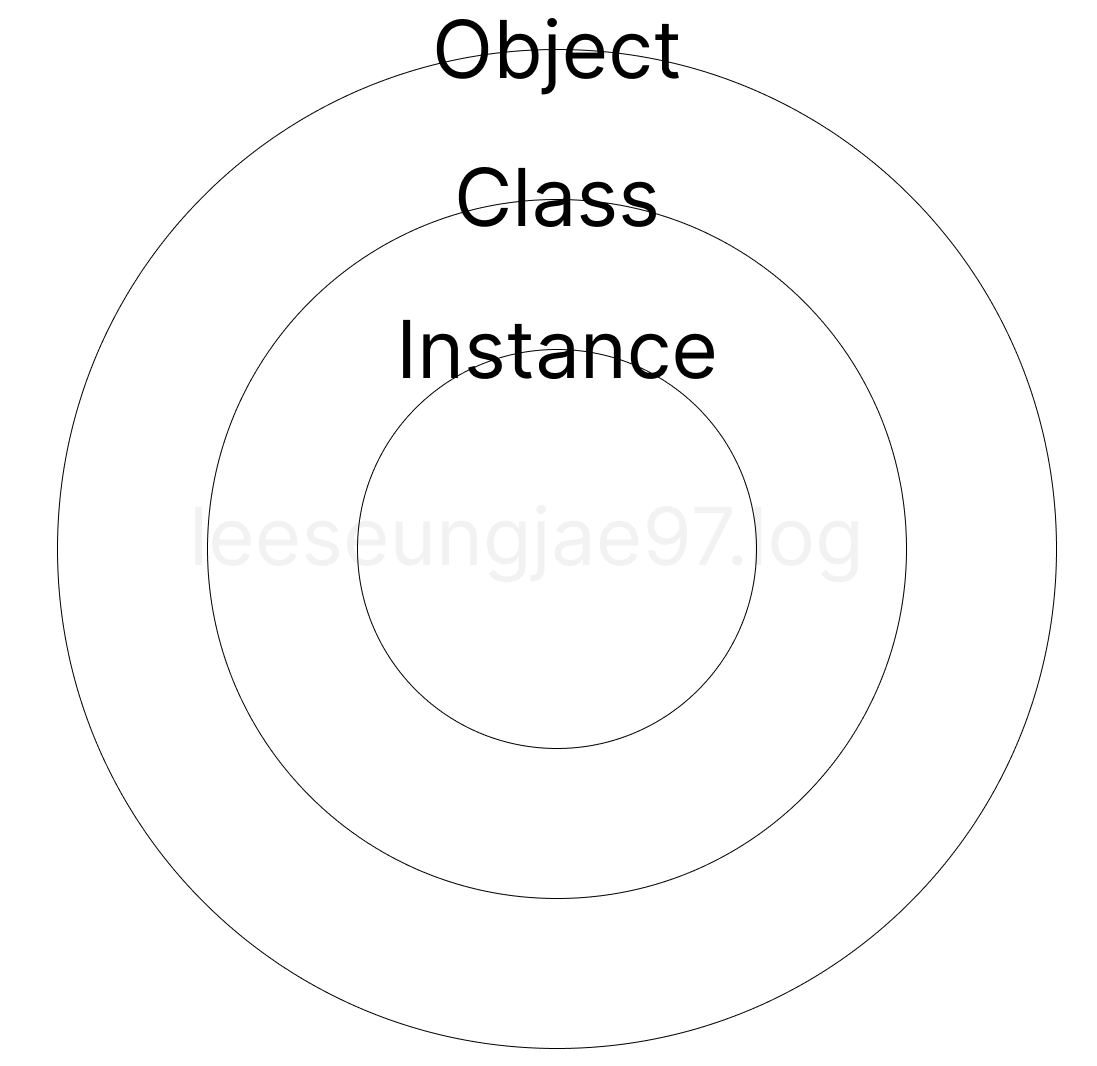
모든 데이터들은 Object인데, Instance는 데이터 중 하나고Instance는 Class가 메모리에 런타임에 올라오면 생성되는 Object를 뜻한다.Instance가 Object OObject가 Instance X
캡슐화
데이터 은닉과 자율성.
Class→
코드의 복잡성으로부터 분리한다는 추상화와 같은 궁극적인 목적이 있지만,
접근성 측면에서 코드의 안전성에 더 중점을 둔다.
캡슐화를 통해 변수와 함수를 의도된 용도로 사용하도록 보장한다.
코드에서 변수 값이나 객체 속성을 쉽게 변경할 수 없게하고, 의도된 대로 작동하도록
코드를 캡슐화한다.
접근 제한자(public, protected, private)로 내부 변수, 함수 사용을 막고
지정한 함수만 호출하게 만든다.
추상화
복잡한 내부 구현을 단순한 인터페이스 뒤로 숨기는 것.
다른 프로그래머에게 복잡한 코드를 제거하고 필요한 기능만 노출하는 과정이다.
세부 사항을 추상화하고 접근 가능한 함수를 제공해, 세부 내용없이 함수만 사용하면
해당 기능을 사용할 수 있게 한다.
상속
지식의 공유와 분류.
Class→
부모 Class 기반으로 자식 Class를 만들 수 있는 기본 Class를 생성하는 과정을 말한다.
자식 Class는 부모 Class의 모든 기능을 계승해, 서로 필요한 코드를 재작성할 필요성을 줄일 수 있다.
다형성
동일한 메시지에 대해 서로 다른 방식으로 응답하는 능력.
Class→
상속을 사용해 나오는 이점.
부모 Class에서 상속받은 코드에 대해 다양한 기능을 구현할 수 있다.
다형성은 부모 Class의 함수를 재정의하면서 발생하는데, 같은 함수 호출이지만
타입에 따라, 범위 연산자(::)에 따라 어떤 함수가 호출 될지 정해진다.
C++에서는 자식 Class에서 부모 Class의 함수 재정의을 위해서 virtual 키워드가 필요하고,virtual을 통해 만들어진 함수는 런타임에 탐색해, 호출 타입에 맞게 가져온다.
SOLID
C++ OOP는 상속, 가상 함수, 캡슐화를 통해 기능 확장한다.
OOP 초기 프로젝트에서는 상속/가상함수로 유연하지만
시간이 지나면, 기능 추가마다 기존 클래스 수정해야하고, 기존 코드를 방어하며 리팩토링을 해야한다.
OOP는 규모가 커지면 의존성 그래프가 뒤엉킨다.
A가 B 포함
B가 C 상속
C가 D 호출
D가 E 생성의존성 구조를 제어하고 구조적 복잡도를 해결하기 위한 규칙으로 SOLID가 생겼다.
SOLID는 상속 최소화, 인터페이스 분리, 합성 우선을 제시한 규칙이다.
Single Responsibility Principle(SRP) : 클래스는 하나의 이유로만 변경 (캡슐화)
Open/Closed Principle(OCP) : 확장에는 열리고 수정에는 닫힘 (다형성)
Liskov Substitution Principle(LSP): 자식은 부모를 대체할 수 있음 (상속)
Interface Segregation Principle(ISP): 인터페이스는 작게 분리
Dependency Inversion Principle(DIP): 상위 정책이 하위 구현에 의존 x (추상화)
SRP → 캡슐화를 통해 책임 응집을 보장
OCP → 다형성을 통해 확장을 구현
LSP → 상속 관계의 안전성 규칙
ISP → 캡슐화된 인터페이스 분리
DIP → 추상화 의존 구조
캡슐화는 SRP와 ISP의 기반이고,
추상화는 OCP와 DIP를 가능하게 하며,
다형성은 OCP의 구현 수단이면서 LSP 조건을 만족해야 하고,
상속은 OCP를 위한 확장 메커니즘이지만 LSP 제약 하에서만 안전하다.
데이터 중심 프로그래밍(DOP)
DOP(Data-Oriented Programming)는 시스템을 코드(함수)와 데이터로 완전히 분리하여 생각하는 프로그래밍 패러다임
기존 OOP가 Object 중심이라 발생하는 한계점이 있다.
CppCon 2014: Mike Acton "Data-Oriented Design and C++"
동영상에서 DOD 뿐만아니라 게임에서 왜 캐시 효율을 중요하게 여기는지,
프로그램 개발자가 지향해하는 개발 방향이 뭔지와 같은 이야기도 한다.
OOP는
Object중심이라 메모리 비연속적이다.- 가상 함수 호출이나 Thunk는 동적 바인딩 이므로 오버헤드가 있다.
- 복잡한 데이터 구조로 컴파일러 최적화가 힘들다. (컴파일러는 마법 도구가 아니다)
- 각
Object마다 값을 저장해 동일한 속성이 반복되는 값 낭비가 있다.
DOP는
- 데이터 배치
- 접근 패턴
- 캐시 효율
- 변환 중심 처리
class Particle {
public:
void update() {
position += velocity;
life -= decay;
}
private:
float position;
float velocity;
float life;
float decay;
};
std::vector<Particle> particles;
// 파티클 초기화
for (int i = 0; i < 100000; ++i) {
particles.emplace_back(/* 초기값 */);
}
// 매 프레임마다 업데이트
for (auto& particle : particles) {
particle.update();
}DOP→
struct ParticleData {
std::vector<float> positions;
std::vector<float> velocities;
std::vector<float> lives;
std::vector<float> decays;
};
void updateParticles(ParticleData& data) {
size_t count = data.positions.size();
// 루프 벡터화를 위해 단순한 연산 유지
for (size_t i = 0; i < count; ++i) {
data.positions[i] += data.velocities[i];
data.lives[i] -= data.decays[i];
}
}
ParticleData particles;
// 파티클 초기화
for (int i = 0; i < 100000; ++i) {
particles.positions.push_back(/* 초기값 */);
particles.velocities.push_back(/* 초기값 */);
particles.lives.push_back(/* 초기값 */);
particles.decays.push_back(/* 초기값 */);
}
// 매 프레임마다 업데이트
updateParticles(particles);https://ludens92.tistory.com/8
friend class
두 Class가 너무 밀접해 서로를 다 알야할 때 사용한다.friend로 선언된 클래스는 상대방의 private, protected멤버에 직접 접근할 수 있다.
class A
{
private:
int data = 7;
friend class B;
}
class B
{
public:
void PrintA(A& a)
{
a.data; // 접근 가능.
}
}A가 B를 friend선언하면 A는 B의 private, protected를 볼 수 없다.A가 B를 friend선언해도 A를 상속받는 C가 B를 알수 없다.
서로가 friend일 때, 컴파일러는 A를 읽으려면 B가 필요하고, B를 읽으려면 A가 필요하다.
이럴 때 전방선언을 통해 B를 미리 알려줘야한다.friend class B자체가 전방 선언 역할을 겸한다.friend B와 같이 간단 표기하면 전방 선언을 써줘야한다.
class B;
class A
{
public:
friend class B;
B m_b;
void Func(B b);
}
class B
{
private:
int a = 0;
friend class A;
}
void A::Func(B b) {}이 관계는 A와 B가 하나의 클래스나 다름 없는 상황이다.
전방선언
컴파일러에게 타입의 이름을 유효한 식별자로 등록한다.
컴파일러는 이름은 알지만 크기는 모르는 상태로
해당 타입을 변수로 주소값은 담을 수 있지만, 실제 Instance실체를
메모리에 생성하거나 멤버에 직접 접근하는 것은 불가능하다.
실제 class가 나타나기 전까지 불완전한 타입으로 있다가
실제 class의 정의가 등장해야 완전한 타입으로 사용가능하다.
전방선언이 나오면 같은 Scope의 동일한 이름의 class, 변수, 함수 선언이 숨겨진다.
struct s { int a ; } ;
struct s ; // 아무것도 하지 않음 (s는 이미 이 범위에서 정의됨)
void g ( )
{
struct s ; // 새로운 지역 구조체 "s"의 전방 선언
// 이 선언은 이 블록의 끝까지 전역 구조체 s를 숨긴다.
s * p ; // 로컬 구조체 s에 대한 포인터
// 이 구역에선 아직 s에 접근할 수 없다.
struct s { char * p ; } ; // 로컬 구조체 s의 정의
p->p; // 이제 접근 가능.
}전방선언은 매개변수로써, 리턴값으로써도 올 수 있음
class U;
namespace ns
{
class Y f(class T p); // declares function ns::f and declares ns::T and ns::Y
class U f(); // U refers to ::U
// can use pointers and references to T and Y
Y* p;
T* q;
}https://en.cppreference.com/w/cpp/language/class.html#Forward_declaration
include, define
#include는 소스 코드를 복사하여 붙여넣기를 뜻한다.
#include <파일> : 표준 라이브러리 경로에서 파일을 찾는다.#include "파일" : 현재 소스 파일이 있는 디렉터리부터 찾기 시작한다.
없으면 표준 경로를 뒤진다.
전방선언을 써서 #include를 줄일 수 있다.#include는 겹치면 같은 소스 코드를 불러올 수 있어서#pragma once나 include guard를 사용해야한다.
#pragma once // 헤더 상단에 이걸 쓰거나
// OR
# ifndef MY_HEADER_H // include guard
# define MY_HEADER_H
// 내용
#endif#define은 C때부터 사용되는 텍스트 교체 도구이다.#define PI 3.14를 하면 전처리 과정에서 PI를 3.14로 바꿔버린다.
#define SQURE(x) ((x) * (x)) 함수처럼 쓸 수 있다.
단순히 글자를 바꿔 끼우는 것이라 디버깅이 거의 불가능하다.
C++에서 #define의 역할을 대신하는 기능들이 있다.
constexpr은 타입 체크를 수행하고 변수처럼 다를 수 있어 안전하다.inline은 컴파일러에게 함수 inlining 최적화를 사용하게 한다.inline void Func() { cout << "Do something\n"; } Func(); // 이 함수 호출은 컴파일러의해 cout << "Do something\n"; // 이걸로 치환된다.template은 타입 확인 가능한 범용적인 코드를 생성한다.#define MAX(a, b) ((a) > (b) ? (a) : (b)) // 템플릿: 안전함 (타입별로 인스턴스 코드를 자동 생성) template <typename T> T Max(T a, T b) { return (a > b) ? a : b; }
Object란 코드 영역에 단 하나만 존재하는 로직(멤버 함수)을 공유하며,
메모리(Stack/Heap) 위에서 this라는 주소값으로 식별되는 순수한 데이터(변수)의 실체이다(instance).
문제
객관식은 생각할 여지를 안줘서 서술형으로 바꿨다.
- nullptr인 포인터로 멤버 함수를 호출해도 터지지 않는 경우가 있습니다. 그 이유를 this 포인터의 전달 방식과 관련지어 설명하세요.
- 멤버 함수가 100개 있는 클래스와 1개 있는 클래스의 인스턴스(객체) 크기 차이는 얼마나 날까요? 그 이유는?
- 초기화 리스트가 생성자 몸체 안에서 대입(=)하는 것보다 왜 물리적으로 더 빠른지 설명하세요.
- 소멸자를 private으로 만들면 어떤 제약이 생기며, 이를 어떻게 활용할 수 있나요? (언리얼/유니티 예시 환영)
- class와 struct를 배열로 만들 때, 왜 메모리 배치(Value vs Pointer)가 성능의 핵심이 되는지 설명하세요.
- 복사 생성자의 매개변수가 MyClass(MyClass other)처럼 참조자(&)가 아니면 발생하는 치명적인 문제는?
- 얕은 복사(Shallow Copy)와 깊은 복사(Deep Copy)의 차이를 힙(Heap) 메모리 주소 관점에서 설명하세요.
- p2 = p1;은 복사 생성자일까요, 복사 대입 연산자일까요? 상황에 따른 차이를 설명하세요.
- 이동 생성자(Move Constructor)에서 원본 객체의 포인터를 nullptr로 밀어버리지 않으면 어떤 사고가 발생할까요?
- RVO(복사 생략) 최적화가 일어날 때, 컴파일러는 물리적으로 어떤 방식으로 인스턴스 생성을 생략하나요?
- 전방 선언(Forward Declaration)만 된 클래스를 멤버 변수로 가질 수 없는 이유를 컴파일러의 메모리 크기 계산 관점에서 설명하세요.
- friend class 선언이 전방 선언의 역할을 겸한다는 것은 구체적으로 어떤 의미인가요?
- 전방 선언을 적극적으로 활용하면 빌드 시간(Compilation Time)이 단축되는 물리적인 이유는 무엇인가요?
- 상속 관계에서 부모 클래스의 소멸자에 virtual을 붙이지 않으면 발생하는 메모리 누수 시나리오를 설명하세요.
- DOP(Data-Oriented Programming)에서 왜 데이터(변수)와 로직(함수)을 분리하라고 강조하나요?
- Unity의 ECS에서 Entity가 인스턴스가 아닌 '단순한 ID(정수)'로 설계된 이유를 성능 관점에서 설명하세요.
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.