개체의 메모리 주소를 저장하는 변수.
주소를 통해 데이터를 간접 참조 할 수 있다.
int*,float*,MyClass*- 역참조를 통해 주소가 가리키는 값을 읽거나 쓸 수 있음
int* p = new int(20); *p = 10; int y = *p; - 주소 값 자체도 정수처럼 연산 가능(배열에서 많이 사용)
vector<int> nums(10); for(int i = 0; i < nums.size(); ++i) nums[i] = i; int* p = nums.data(); cout << *(p + 2); // nums[3] nullptr을 가질 수 있음.
핵심 사용처
- 동적 메모리 할당
- 함수에 큰 데이터 복사 비용 방지
- 배열, 문자열, 자료구조 구현
참조(Reference)
다른 변수의 별칭(alias)으로 사용됨
int a = 5;
int& b = a; // 이제부터 b는 a의 aliasT& : lvalue에만 바인딩 가능, lvalue 참조 선언자라고 한다. 명명된 변수를 참조하는데 사용함.
int&r = a; // ⭕ lvalue
int&r = 10; // ❌ prvaluecategory value에 대해서는 표현식 참고
T&& : xvalue, rvalue에만 바인딩 가능, rvalue 참조 선언자라고 한다. 임시 개체를 참조하는데 사용함
int&& r = 10; // ⭕ prvalue
int&& r = std::move(a); // ⭕ xvalue
int&& r = a; // ❌ lvalue참조자는 재바인딩이 안된다.
int a = 5;
int& b = a; // a의 주소로 바인딩
int c = 6;
b = c; // a에 6대입참조자는
- 참조하고자 하는 객체를 미리 알고 있을 때,
- 다른 객체를 바꾸어 참조할 일이 결코 없을 때
- 포인터를 사용하면 문법상 의미가 어색해지는 연산자를 구현할 때
사용이 권장되고 그 외에는 포인터 사용이 권장된다.
// 참조자를 쓰면 좋은 경우
vector<int> v(10); // 크기 10의 int 벡터를 만듭니다.
>v[5] = 10; // 이 대입 연산의 대상은 >operator[]의
// 반환값.
// 만일 operator[]가 포인터를 반환하면,
// 조금 어색한(포인터의 벡터처럼 보이는)
// 형태가 됨
*v[5] = 10;컴파일러는 내부적으로 참조자를 T* const로 구현한다.
함수에 참조를 넘기면, 실제로는 객체의 주소값이 레지스터나 스택을 통해 전달된다.
일단 주소값을 저장할 공간이 필요하니까 내부적으로 포인터와 같이 8바이트(64비트)를 차지한다.
함수 내부에서 참조를 사용할 때마다 컴파일러가 자동으로 역참조(*)코드를 삽입해 원본에 접근한다.
int& ref = a;
→ int* cosnt ref = a 주소값
ref = 20;
→ *ref_internal = 20;어셈블리 코드를 보면 확인 가능하다.
43: int& ref = a;
lea rax,[a] ; a의 주소값 rax에 담음
mov qword ptr [ref],rax ; rax(a의 주소)를 ref라는 메모리 위치에 저장ref가 qword ptr로 사용되고있는게 보인다.
또 바로 값을 바꾸는게 아니라 주소를 먼저 꺼낸 뒤 그 주소가 가리키는 곳에서 값을 바꾼다.
44: ref = 20;
mov rax,qword ptr [ref] ; ref에 저장된 값(즉, a의 주소)을 rax로 읽어옴
mov dword ptr [rax],14h ; rax가 가리키는 주소([rax])에 14h(20)를 써넣음
45: return 0;참조자는 null 참조자 같은건 없기 때문에 유효성 검사할 필요가 없다.
void func(int& a)
{
// 검사할 필요 없음
a = 10;
}참조 축약 규칙
참조의 참조는 없지만, template이나 auto를 사용하다보면
내부적으로 참조가 겹치는 상황이 발생한다. 이때 컴파일러가 하나의 참조로 합쳐주는 규칙& + && = &&& + && = &&
template <typename T>
void func(T&& t) // rvalue 참조만 받는 함수(만능 참조, 아래 rvalue 참조 확인)
{
t = 10;
}
int a = 10;
// lvalue 전달
// T는 int& → 인자는 int& &&가 된다 → int&로 축약
// 참고로 template 쓰지않으면 여기는 컴파일 에러가 난다.
// 디셈블 : func<int &> (07FF723622780h)
//
func(a);
// rvalue 전달
// T는 int → 인자는 int&&가 된다 → int&&로 축약
// 디셈블 : func<int> (07FF723622830h)
func(10);간단하게 &가 하나라도 섞이면 &가 된다.
참조와 주소연산자 비교
| 비교 항목 | 참조(T&) |
주소연산자(&expr) |
|---|---|---|
| 역할 | 별칭(alias) 생성 | 객체의 실제 메모리 주소를 얻음 |
| 적용 위치 | 타입에 붙음 | 표현식에 붙음 |
| 실행 시점 | 컴파일 시 바인딩 | 런타임에 주소 계산 |
| 생성되는 것 | lvalue | prvalue 주소값 |
| 재바인딩 | 불가능 | 해당 없음 |
| &이 붙는 방식 | int& r → 문법 일부 |
&a → 연산자 |
| 포인터와 관계 | 포인터 아님 | 포인터에 저장 가능한 값 생성 |
Reference, Primitive
Primitive : 기본적으로 제공하는 가장 작은 단위의 데이터 타입들int, float, double, char 등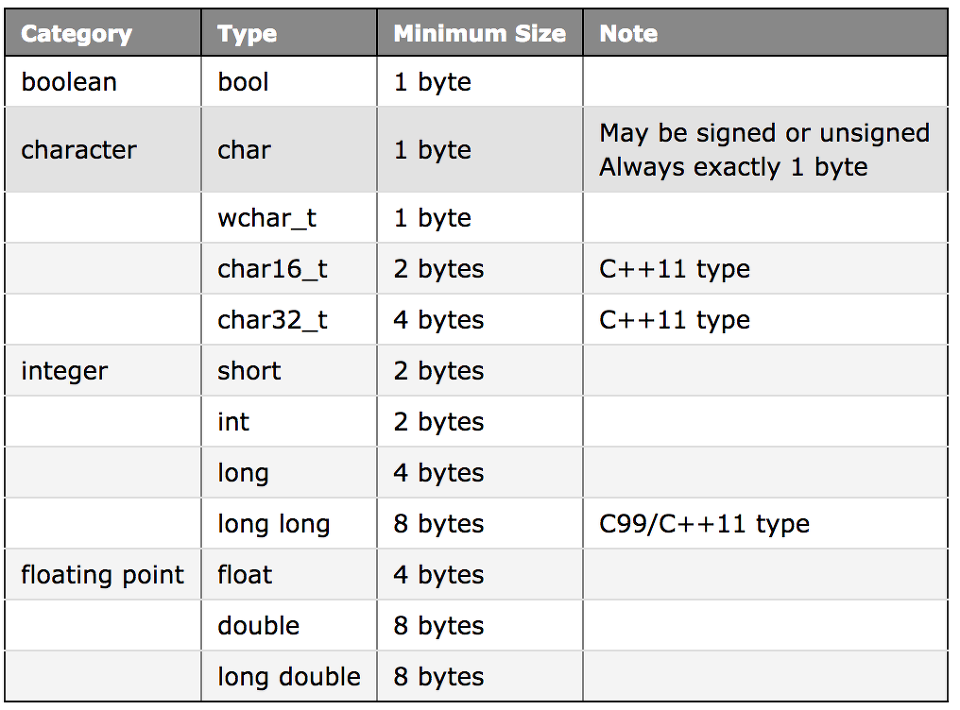
https://boycoding.tistory.com/149
대부분 스택영역에 할당되고, 크기가 고정되어 있어 빠름
다른 변수에 대입할 때 값의 복사가 일어난다.
눈여겨 볼 부분은 복사(copy)와 전달(call/pass)이다.
복사(copy)
shallow copy(얕은 복사)
주소값만 복사
복사본을 수정하면 원본도 같이 바뀌거나, 한쪽이 해제 하면 다른 한쪽은 댕글링 포인터가 됨.
T* t = new T();
T* t2 = t; // 얕은 복사
delete t;
// t2는 댕글링
void func(int& a)
{
a = 10; // 얕은 복사
}deep copy(깊은 복사)
실제 데이터가 담긴 새로운 메모리 공간을 할당하고 내용물을 채움
T* t = new T();
T* t2 = new T();
t2->data = t->data;전달(pass/call)
값에 의한 전달
void passByValue(int a) { } // a에 10전달
int value = 10;
passByValue(value);
cout << value // 10;포인터에게 주소(Pointer) 전달
void passByPointer(int* a) { if(nullptr != a) a = 90; }
int value = 10;
passByPointer(&value);
cout << value; // 90참조자에게 참조(Reference) 전달
void passByReference(int& a) { a = 900; }
int value = 10;
passByReference(value);int a = 5;
int c = 6;
int& b = a; // 이제부터 b는 a의 alias임 ( b == a)
b = c; // a에 6 대입
int& d = b; // 이제부터 d는 b의 alias임 즉 a의 alias ( d == b == a)
int* p = &x;
int*& db = p; // int 포인터 p의 alias참조 전달은 함수의 리턴값으로 사용하면 안된다. 항상 댕글링 포인터가 되기 때문.
T& func()
{
T* t = new T();
return *t; // 메모리 누수 + 댕글링 포인터
}참조 전달은 컴파일러가 내부적으로 포인터를 사용하여 주소를 전달하지만,
문법적으로는 원본 변수의 별칭(alias)로 동작하게 한다.
포인터 산술
+, -, ++, --
- p + n → p가 가리키는 타입 T의 크기 * n 만큼 이동
- p - n → 반대 방향으로 이동
- ++p → p = p + 1
- --p → p = p - 1
내부적 동작
- 새주소 = 기존 주소 + n *
sizeof(T) - 배열 기준
- 배열이 아닌 곳에 포인터 산술하면 Undefined Behavior(UB)
- 포인터 끼리 연산
int* p = &arr[4]; int* q = &arr[1]; int diff = p - q; // 결과: 3
void*의 경우 가리키는 대상 크기를 알 수 없으므로 포인터 산술을 사용할 수 없다.
sizeof(T)
컴파일 타임에 계산되는 컴파일 타임 상수
정렬, 패딩이 포함되는 최종 객체의 메모리에서 차지하는 바이트 수를 계산한다.
struct Node
{
int y, x;
};
// Node == 8byte내용물이 없는 클래스의 크기는 1바이트이다.
struct A {};모든 객체는 서로 구분 가능한 고유한 주소를 가져야 한다.
컴파일러가 최소 단위인 1바이트를 강제로 할당하고 각 객체에 고유 주소를 부여한다.
padding
연속해 데이터가 있는 구조(클래스, 구조체)에서, 데이터를 정렬하기 위해 추가되는 데이터.
패딩을 위해 데이터가 낭비되지만 비정렬된 데이터를 가져오는 비용보다 합리적인 소모이다.
virtual이 있는 클래스에 경우vptr로 인해 패딩이 추가될 수 있음struct A { int x; virtual void foo() {} }; struct B { int x; };A는 생성된vptr때문에 alignment기준이 8byte가 됨.
int값에 4byte를 더해 총 16byte가 된다.B는 4byte
연속한 지역변수나 전역변수는?
컴파일러가 정렬시켜 배치함.
alignment(정렬 배수)
CPU의 효율을 높이기 위해서 데이터 정렬한다.
변수나 데이터가 메모리에서 특정 배수의 주소에서 시작할 수 있도록 정렬.
CPU는 한 번에 일정 크기의 데이터를 읽도록 설계됨.
int i[3]이 있을때 CPU는 i에 접근해 4byte씩 끊어가며 읽으면 된다. int i[3]은 4byte의 alignment가 존재.
구조체, 클래스의 경우 이런 배수를 맞추기위해서 패딩함.
alignment의 크기는 구조체, 클래스 내부의 가장 큰 자료형의 크기로 정해진다.
어떤 타입이든 정해진 alignment크기로 한번에 접근할 수 있다.
alignment가 지정되어 있지 않으면 CPU가 한번에 읽지 못할 수 있고
두번이상으로 메모리에 접근하게 된다.
union Union
{
short s;
};
struct Node
{
int y;
int x;
--- 8byte
short s; + padding 6byte
--- 16byte
double d;
--- 24byte
Union u;
Union u2; + padding 4byte
--- 32byte
double d2;
--- 40byte
}
size = 40bytes, alignment = 8bytes; union Union
{
short s;
};
struct Node
{
int y;
int x;
--- 8byte
double d;
--- 16byte
double d2;
--- 24byte
short s;
Union u;
Union u2; + padding 2byte
--- 32byte
}
size = 32bytes, alignment = 8bytes순서만 바꿔도 size가 달라짐.
함수 포인터
함수를 값처럼 가리키고, 전달, 호출하기 위한 포인터
함수를 선언하면 실행 파일의 코드 영역에 위치하게 되고
위치를 표현하는 주소가 생김. 해당 함수의 주소를 저장했다가
사용할 수 있다.
함수의 시그니처가 일치해야 저장할 수 있고, 상태를 가질 수 없다.
반환형 (*포인터이름)(매개변수들)int Add(int a, int b)
{
return a + b;
}
int (*op)(int, int) = Add;
Callable
()를 붙여서 호출할 수 있는 것을 Callable로 정의struct sB { void operator()(float, float) {} } sB sb; sb(3.5, 3.5); // 객체를 함수처럼 사용, // sb.operator()(3.5, 3.5) 형태
---
`typedef`나 `using`을 통해서 코드 가독성을 개선해 사용하는게 좋다.
```cpp
typedef void (*Func)();
using Func = void (*)();함수 포인터를 이용한 콜백 함수 지정
void OnComplete()
{
// 완료 시 수행
}
void Run(void (*callback)())
{
callback();
}
Run(OnComplete);
함수 포인터를 배열로 저장해 사용할 수 있다.
int Add(int a, int b) { return a + b; }
int Sub(int a, int b) { return a - b; }
int (*ops[2])(int, int) = { Add, Sub };
int result = ops[0](5, 3); // Addstd::function이나 람다사용으로 대신할 수 있음
auto f = []()
{
}
std::function<void()> f = Foo;lambda
이름없는 익명 함수 객체를 만드는 문법[캡처](매개변수) {함수 본문}
컴파일러는 람다를 만나면 내부적으로 operator()가 오버로딩된 이름 없는 클래스를 생성한다.
auto lambda = [](int a, int b) { return a + b; }함수 포인터와 람다의 차이는 '주변 변수를 묶어서 들고다닐 수 있나'이다.
람다는 코드에 작성한 표현식 그 자체를 의미한다
캡처를 사용하게 되면 람다에 외부 변수를 넣을 수 있다.[v]값 캡처, [&v]참조 캡처를 사용할 수 있다.
람다 표현식에 의해 생성된 실행 시점의 객체를 closure라고한다.
클로저는 람다가 선언된 환경을 캡처하고 간직하고 있는 상태를 의미한다.
람다가 설계도라면, 클로저는 그 설계도를 바탕으로 캡처된 변수들을 들고 실제 생성된 객체이다.
int factor = 10;
auto multiply = [factor](int n) { return n * factor; }; // factor를 클로저 내부에 바인딩참조 캡처를 사용할 때는 생명 주기를 신경써야 한다.
auto GetLambda()
{
int local_val = 10;
return [&local_val]() { cout << local_val << '\n'; };
}
auto my_lambda = GetLambda();
my_lambda(); // 이미 파괴된 local_val에 접근 (Dangling)class Player
{
public:
int hp = 100;
auto GetHealFunc() {
// [=] this 포인터를 복사함
return [=]() { hp += 10; };
}
};
auto p = new Player();
auto heal = p->GetHealfunc();
delete p;
heal(); // 파괴된 객체의 this->hp에 접근즉시 실행되는 람다가 아니면 참조 캡처를 지양해야하고
클래스 멤버 함수 내에서 람다를 반환하거나 저장할 때 this 캡처도 경계해야한다.
수명이 불확실한 경우에는 스마트 포인터로 값을 캡처해서 생존을 보장해야한다.
같이 사용되는 키워드
const: 포인터를 초기화 후 수정할 수 없음constexpr(compile-time constant experssion): 컴파일 타임에 값이 확정되어야함. 동작은const와 같음, 함수, 생성자에도 적용가능const와constexpr변수의 주요 차이점은const변수의 초기화가 런타임까지 지연될 수 있다는 것입니다.constexpr변수는 컴파일 시간에 초기화되어야 합니다. 모든constexpr변수는const입니다.
https://learn.microsoft.com/ko-kr/cpp/cpp/constexpr-cpp?view=msvc-170volatile: 컴파일러의 최적화를 막아줌, 캐싱되지 않아서 메모리에서 값을 다시 로딩해오게 만듬.
값이 외부 요인으로 바뀔 수 있는 경우에 캐싱하지 않고 메모리에서 값을 로딩해 값 확인, 임베디드/하드웨어 접근에 많이 쓰임const int cInt = 10; cout << cInt; // 10이 출력 int* pInt = (int*)&cInt; *pInt = 30; cout << cInt; // 10이 출력 // const 변수이므로 상수로 판단한 컴파일러가 최적화해서 // 기존 값을 그대로 사용함. ------------ volatile const int cInt = 10; int* pInt = (int*)&cInt; *pInt = 30; cout << cInt; // 30이 출력 // volatile을 통해 캐싱값을 사용하지 않겠다라고 선언. // 결과적으로 const 변수의 값을 바꿈C++ 컴파일러는 변수가 코드 상에서 변경되지 않으면 레지스터에 저장해두고 메모리 접근을 생략함.
std::nullptr:null 포인터 리터럴으로 아무 것도 가리키지 않는 값. 포인터 초기화, 비교, 무효화에 사용됨
기존에 사용하던NULL이 0으로 정의된 매크로이어서 함수 오버로딩 시func(int)가 호출되던 모호성 발생 가능함.nullptr의 타입은nullptr_t으로 이러한 모호성을 없앤type-safe한 리터럴이다.typedef decltype(nullptr) nullptr_t;nullptr_t a = nullptr; if (a == nullptr) // OK cout << "nullptr\n"; if (a == 0) // OK cout << "0\n"; if (a == NULL) // OK cout << "NULL\n";void func(int a) { cout << "int\n"; } void func(nullptr_t a) { cout << "nullptr_t\n"; } void func(int* a) { cout << "int*\n"; } func(a); // nullptr_t 출력 cout << sizeof(nullptr) << '\n'; // 8 cout << typeid(nullptr).name() << '\n'; // std::nullptr_t
스마트 포인터
RAII 원칙에 따라 동적 할당된 객체의 소유권과 생명 주기를 자동으로 관리하는 객체
C++11에 추가되었다.
RAII(Resource Acquisition Is Initialization)
자원의 수명을 객체의 수명과 일치시키는 디자인 패턴
생성자에서 자원을 획득/할당하고, 소멸자에서 자원을 해제/반납한다.
unique_ptr
단일 소유권을 가지는 스마트 포인터
원시 포인터와 동일한 성능(보통 8byte)을 유지하면서 메모리 누수를 방지, 컴파일 타임에 형태가 결정된다.
스코프가 끝나면 알아서 delete하며, unique_ptr은 복사 생성자와 대입 연산자를 삭제했기 때문에
복사 생성, 복사 대입이 불가능하고 이동 생성, 이동 대입만 가능하다(std::move)
소유권을 강제함으로 중복 호출이 없고 예외가 발생하거나
스코프를 벗어나면 자동으로 delete 발생
custom deleter를 설정할 수 있다.
auto file = std::unique_ptr<FILE, decltype(&fclose)>(fopen("a.txt","r"), fclose);
// file 소멸시 fclose 자동호출삭제자 내부에 여러 변수, 함수를 가질 수 있기 떄문에 크기가 커질 수 있다.
struct StatefulDeleter {
int id; // 상태(데이터)를 가짐
void operator()(int* p) { delete p; }
};
// sizeof(ptr) == 8(포인터) + 4(int id) + padding = 16바이트
unique_ptr<int, StatefulDeleter> ptr(new int(10), StatefulDeleter{101});그래도 컴파일 타임에 컴파일러가 인라인 최적화를 해주니까 shared_ptr 삭제자 보다 최적화가 된다.일반 소멸자 ≈ unique_ptr 삭제자 > shared_ptr 삭제자
unique_ptr은 타입과 삭제자가 묶이기 때문에 삭제자가 다르면 이동 대입 할 수 없다.
// 삭제자 A
struct DeleterA {
void operator()(int* p) { delete p; }
};
>
// 삭제자 B
struct DeleterB {
void operator()(int* p) { delete p; }
};
>
unique_ptr<int, DeleterA> p1(new int(10));
unique_ptr<int, DeleterB> p2(new int(20));
// p1 = move(p2); // ❌ 컴파일 에러, 시그니처가 달라서(다른 타입임) 대입 불가하지만 custom deleter에 별내용이 없으면, 별도의 참조 카운트를 관리하지 않아서
원시 포인터와 크기가 같고 성능차이 거의 없다.
함수의 리턴값으로 사용을 제일 권장된다.
unique_ptr<T> func()
{
unique_ptr<T> tup{};
return std::move(tup);
}리턴된 unique_ptr은 타입 자체로도 안전하고, 소유권 이전이 명확하다.shared_ptr로도 전환이 가능하다.
이런 코드도 가능하다.
unique_ptr<T> func()
{
unique_ptr<T> tup{};
return tup;
}리턴 시점에 tup는 사라질 rvalue로 간주되어서
자동으로 move가 수행된다. 소유권이 호출한 쪽으로 넘어간다.
최신 컴파일러는 복사 최적화(Copy Elision)가 발생하기 때문에
이동 없이 호출한 쪽의 메모리 공간에 객체를 처음부터 생성한다.
make_unique
할당과 생성이 모두 원자적으로 처리된다.make_unique는 커스텀 삭제자를 인자로 받을 수 없다.
C++14에 추가되었다. 이전엔 만들어썻다.
template<typename T, typename... Args>
std::unique_ptr<T> _make_unique(Args&&... args)
{
return std::unique_ptr<T>(new T(std::forward<Args>(args)...));
}제어 블럭이 없어서 함수로 만들어도 성능 이득이 없었기때문에 늦게 추가되었다고
shared_ptr
원자적 참조 카운트를 기반으로 하는 스마트 포인터.shared_ptr끼리 객체를 공유하면서 소유권 관리 참조 카운트를 관리하므로 부하가 있다.
카운트는 shared_ptr끼리 참조할 때만 올라감shared_ptr이 서로를 참조하고 있으면 순환 참조 문제 발생.
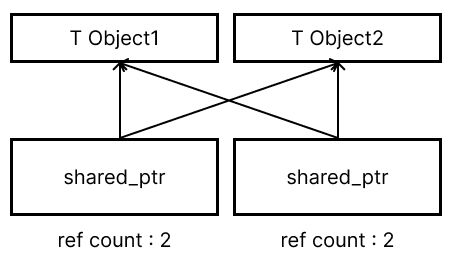
control block으로 공유 상태 저장control block이 별도의 메모리를 가지기 때문에 shared_ptr은 런타임에 형태가 결정된다.
control block
shared_ptr이 관리하는 공유 상태를 저장하는 별도의 메모리 구조
참조 카운트, weak count, custom deleter 등이 포함됨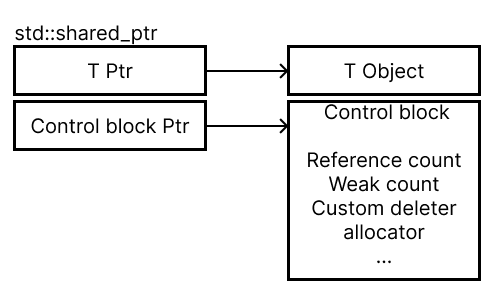
make_shared()으로 shared_ptr을 생성할 때 마다 control block이 생성된다.
내부의 참조 카운트는 원자적 연산으로 구현되어 있어서
여러 스레드에서 동시에 동일한 객체를 가리키는 shared_ptr을 복사하거나 소멸시킬 때
참조 카운트 증감은 스레드 안전하다.
shared_ptr객체는 내부적으로 객체의 주소를 담은 포인터와 제어 블록의 주소를 담은 포인터
두개의 포인터를 가진다.
만약 한 스레드가 shared_ptr 변수(p1)에 다른 객체를 대입(p1 = p2)하고 있는데 동시에
다른 스레드가 p1을 읽으려 한다면?
shared_ptr은 두개의 포인터를 업데이트 해야하는데 이 과정은 원자적이지 않다.
한 포인터는 바뀌었는데 다른 포인터는 바뀌지 않은 중간상태를 읽게 될 위험이 있다.
스마트 포인터는 자원 자체를 보호하는 뮤텍스가 아니다.
동기화가 필요하다면 스마트 포인터 외에도 동기화 문법이 필요하다.
shared_ptr은 원시 포인터와 섞어 쓰면 안된다. 이중해제가 발생할 수 있다.
T* ptr = new T();
shared_ptr<T> p1(ptr);또 포인터로 다른 shared_ptr을 만든다면 하나의 원시 포인터로 두개의 제어 블록이 생성된다.
shared_ptr<T> p2(ptr);두 shared_ptr은 서로의 존재를 모르니까 이중 해제가 발생한다.ptr자체를 해제할 수 있으니 원시 포인터와의 사용은 여러모로 단점만 있다.
비슷한 맥락으로 this와 섞어 쓰게되면 이중 해제가 발생한다
return shared_ptr<T>(this);외부에서 이미 관리중인 control block과 별개의 새로운 control block이 생긴다.
같은 객체를 두개의 독립적인 스마트 포인터가 관리하게 되어 이중해제 발생.
make_shared
make_shared<T>()를 통해 shared_ptr을 생성한다.
std::make_shared<T>() : 메모리 할당이 한번 일어남 (T객체와 control block을 같이 할당)
할당과 생성이 원자적으로 일어난다. T객체와 control block을 하나의 메모리 덩어리로 일괄 할당하기 때문에
성능과 캐시 적중률이 올라간다.make_shared를 사용하면 커스텀 삭제자를 지정할 수 없다.
shared_ptr<T> p(new T()) : 메모리 할당이 두번 일어남. (T객체, Control Block)new T()를 관리하는게 아니라 T는 shared_ptr이 생성되기 이전에 만들어진 것.
이렇게 되면 메모리 누수가 발생한다.
make_shared로 shared_ptr을 만들면 strong count가 0이 되어도 weak count가 남아 있으면
제어 블록과 객체가 점유한 메모리 전체가 해제되지 않는다.
반면, new를 써서 생성하면 strong count가 0이 되는 순간 객체 메모리가 바로 해제되고 제어 블록만 남는다.
shared_ptr<A> makeShared = make_shared<A>();
shared_ptr<A> makeNew (new A());만들면 default,make_shared로 구분되어 보여진다.
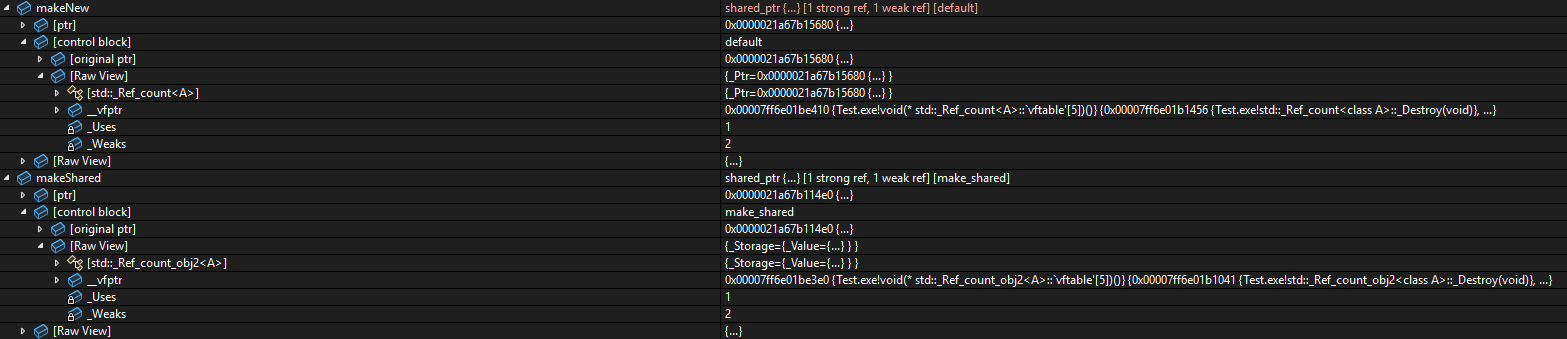
_Weaks가 2인 이유는, MSVC가 제어 블록 자체의 수명을 관리하기 위해
내부적으로 약한 참조를 사용한다.
해제 해보면
weak_ptr<A> fromMakeShared = makeShared;
weak_ptr<A> fromMakeNew = makeNew;
makeShared.~shared_ptr();
makeNew .~shared_ptr();
new로 만든 객체는 없어졌지만, make_shared로 만든 객체는 살아있다.
둘 다 control block은 남아있다.
shared_ptr<A> remakeFromShared = fromMakeShared.lock();
shared_ptr<A> remakeFromNew = fromMakeNew.lock();둘 다 lock은 안된다.

shared_ptr에도 custom deleter를 구현할 수 있다.
shared_ptr의 삭제자는 포인터 외부의 제어 블록 메모리에 저장되기 때문에
unique_ptr과 달리 삭제자가 커도 shared_ptr자체에 영향을 주지 않는다.
삭제자가 제어 블록으로 따로 관리 되기 때문에 타입이 같으면 삭제자가 달라도 대입이 된다.
shared_ptr<int> p1(new int(10), [](int* p){ delete p; });
shared_ptr<int> p2(new int(20), [](int* p){ printf("Special Delete\n"); delete p; });
p1 = p2;unique_ptr ⇄ shared_ptr
unique_ptr → shared_ptrunique_ptr이 관리하던 자원 제어권을 shared_ptr로 넘겨주면 된다.
shared_ptr<B> sbp = make_shared<B>();
unique_ptr<B> ubp = make_unique<B>();
shared_ptr<B> sbp2 = move(ubp);unique_ptr ← shared_ptrshared_ptr에는 이미 여러개의 참조 카운트가 있을 수 있다.
다른 참조에 대해 관여할 수 없으므로 unique_ptr로의 전환은 논리적으로 맞지않다.
그렇기 때문에 허용되지 않는다.
weak_ptr
소유권을 가지지 않는 참조용 포인터
lock으로 관찰 중인 객체의 생존여부를 확인하고, 유효하면
가지고 있는 객체타입으로 shared_ptr을 만들어 낼 수 있다.
weak_ptr은 반드시 shared_ptr로 부터 파생되어야 하고shared_ptr control block의 strong count에 관여하지 않고 weak count가 늘어난다.
shared_ptr은 strong count가 0이 되어 사라져도 control block은 사라지지 않는다.weak count가 남아 있으면 메모리에서 해제되지 않고 유지된다.
이걸로 weak_ptr이 객체의 소멸을 확인할 수 있다.
그렇게 되면 객체가 점유했던 메모리 공간이
해제되지 못하고 제어 블록과 함께 남게된다.
그 결과 객체의 소멸자는 호출되지만, 메모리 반환은 지연된다.
객체의 크기가 매우 크고 weak_ptr이 오래 유지된다면,
오히려 new()를 쓰는 것이 메모리 반환 측면에서는 유리할 수 있다.
그래도 댕글링 포인터의 위험없이 객체의 유효성을 확인할 수 있다는 점은 여전한 장점이다.
| 구분 | unique_ptr | shared_ptr | weak_ptr |
|---|---|---|---|
| 소유권 | 독점 (Single) | 공유 (Shared) | 없음 (Observer) |
| 복사 | 불가 | 가능 | 가능 |
| 이동 | 가능 | 가능 | 가능 |
| 참조 카운트 | 없음 | Strong Count 사용 | Weak Count 사용 |
| 크기 | 8B (가변) | 16B (고정) | 16B (고정) |
| 주요 사용처 | 일반적인 동적 할당 | 자원 공유 | 순환 참조 해결 |
게임 엔진은 자체 포인터 래퍼를 사용한다.
엔진 GC 기반 Intrusive ref counting 자체 스마트 포인터 표준 스마트 포인터 Unreal ✔ (UObject GC) ❌ TObjectPtr, TWeakObjectPtr, TSoftObjectPtr일반 C++ 객체에만 사용 Unity ✔ (C# GC) ❌ Native handle 기반 Smart pointer 없음 CryEngine ❌ ✔ _smart_ptr거의 사용 안 함 Godot ❌ ✔ Ref<T>, WeakRef표준 스마트 포인터 사용 안 함 Cocos ❌ ✔ Ref*retain/release없음 Source ❌ ✔ CRefPtr, EHANDLE없음 Intrusive ref counting: 객체에 참조 카운트를 내장해 사용, control block 사용하지 않음(메모리 해제없음)
댕글링 포인터
유효하지 않은 메모리를 가리키고 있는 포인터
- 이미 해제한
delete/free메모리 - 이미 스코프를 벗어난 객체
- 이미 파괴된 객체
- 이동(move)으로 자원이 넘어간 뒤의 포인터
- 컨테이너 재할당 시
댕글링 포인터가 발생한다.
wild pointer
포인터의 초기화를 생략하면 발생.
초기화가 강요되지 않는 언어의 모든 포인터는 와일드 포인터로 시작한다.char *dp; // wild pointer static char *scp; // static변수는 시작 시 0으로 초기화 // wild pointer가 아님
```
포인터는 메모리의 특정 주소를 직접 가리키는 변수로서,
복잡한 데이터 구조에 효율적으로 접근하고
동적 할당을 통해 자원 수명을 직접 제어할 수 있게 해주지만,
잘못된 참조 시 댕글링 포인터나 메모리 누수 위험이 있어 양날의 검이다.
문제
기본문제 20개
https://gemini.google.com/share/1e7a6f563c48
심화문제 10개
https://gemini.google.com/share/c98344223df6
내용에 대한 질의나, 수정 요청은 저에게 큰 도움이 됩니다.